多平台安装与配置ollama
ollama目前已经支持三种平台的安装(2024年6月16日),Windows,MacOS和Linux
Windows安装
之前版本的ollama,只能通过安装在Windows子系统的方式安装,目前ollama已经支持直接安装在Windows,并且安装完成之后不用再安装cuda等组件支持,直接可以调用显卡算力;
以下用llama3举例:
官网下载和安装ollama
访问官网下载安装包:
这里选择Windows,目前(2024年6月16日)暂时应该只能选择预览版本。
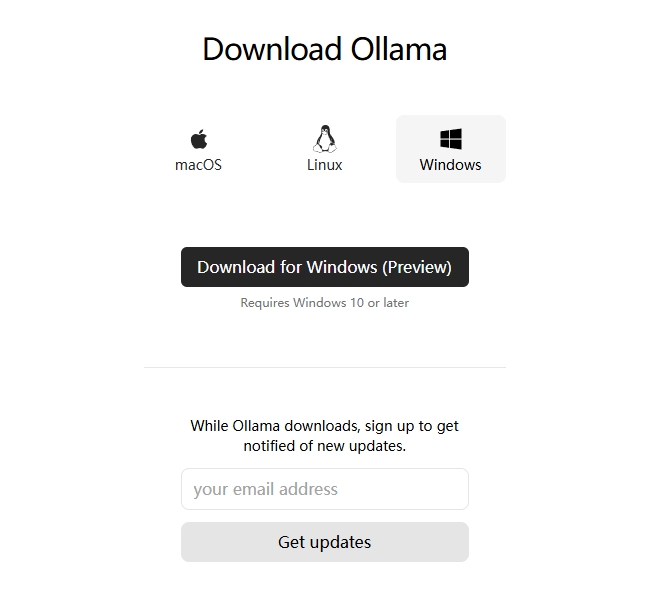
下载并安装即可
Windows配置对应环境变量
Windows–编辑系统环境变量–xxx的用户环境变量–按照需求新增以下配置
配置模型安装位置
默认的模型会下载到C盘,如果你的C盘很小不想变红,建议设置下,因为一个模型大小小则几个G多则上百G,并且建议设置到固态硬盘速度会更快一些
OLLAMA_MODELS=自定义位置
如笔者这里需要安装在D盘的Ollama文件夹,则对应的用户环境变量配置如下:
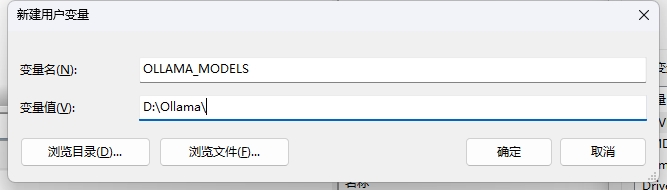
配置完成后在ollama命令中pull的模型就默认放在自定义位置
配置Chat API地址
Ollama提供了两个API访问接口,常用的是Chat。两个API连接默认是127.0.0.1:11434,也即默认只能用本机访问11434端口,可以在浏览器中看到如下效果:
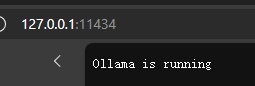
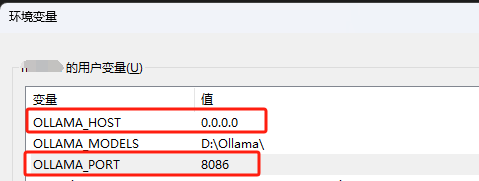
共有两个变量控制,一个OLLAMA_HOST控制访问地址,一个OLLAMA_PORT控制端口
如笔者这里需要设置为局域网可访问,且端口需要修改为8086,则对应的变量应该设置OLLAMA_HOST为0.0.0.0,OLLAMA_PORT为8086:
设置并发请求数量
Ollama可以同时处理多个请求,默认只能处理一个请求,这里如果需要放开,则需要设置OLLAMA_NUM_PARALLEL
如笔者需要Ollama能同时处理5个请求,则需要添加环境变量OLLAMA_NUM_PARALLEL,对应的值设置为5
多模型并发运行
Ollama支持同时运行多个模型,默认也只运行一个模型,这里如果需要同时加载几个模型,则需要设置OLLAMA_MAX_LOADED_MODELS
如笔者需要Ollama能同时运行2个模型,则需要添加环境变量OLLAMA_MAX_LOADED_MODELS,对应的值设置为5
一般该值需要配合变量OLLAMA_NUM_PARALLEL一起配置,比如笔者希望能同时运行3个模型,并且支持3个用户同时请求,那就需要设置红OLLAMA_MAX_LOADED_MODELS=3,OLLAMA_NUM_PARALLEL=3
模型保持运行(模型存活时间)
Ollama默认在最后一次使用模型5分钟之后就会自动卸载掉模型,表现就是模型在第一次使用时生成速度较慢,5分钟内如果再次使用,则生成速度较快,5分钟内没有使用5分钟后再次使用,则模型回复速度又和第一次一样缓慢;
而且目前(2024年6月17日)Ollama有个小bug,在卸载掉模型之后,对应的内存实际上还是存在的,需要手动释放掉,所以建议如果需要长期使用,就让模型一直存活即可,则设置对应的环境变量OLLAMA_KEEP_ALIVE为-1或者24h
Ollama无法释放内存的问题,就需要手动释放内存:
1 2 3
taskkill /F /IM ollama taskkill /F /IM ollama* taskkill /F /IM *ollama
展开
或者powershell中执行
1
Get-Process | Where-Object { $_.Name -match 'ollama' } | ForEach-Object { Stop-Process -Id $_.Id -Force }展开
执行完成命令可以用这个命令查看下Ollama是否有进程, 这个命令是用于在 Windows 系统上列出所有名为 Ollama.Exe 的进程。
1
Tasklist /FI "IMAGENAME Eq *ollama*"
展开
安装模型与使用
正常安装即可使用在命令行执行Ollama相关命令
比如笔者这里需要运行llama3的8b模型,正常流程如下:
Ollama官网搜索该模型
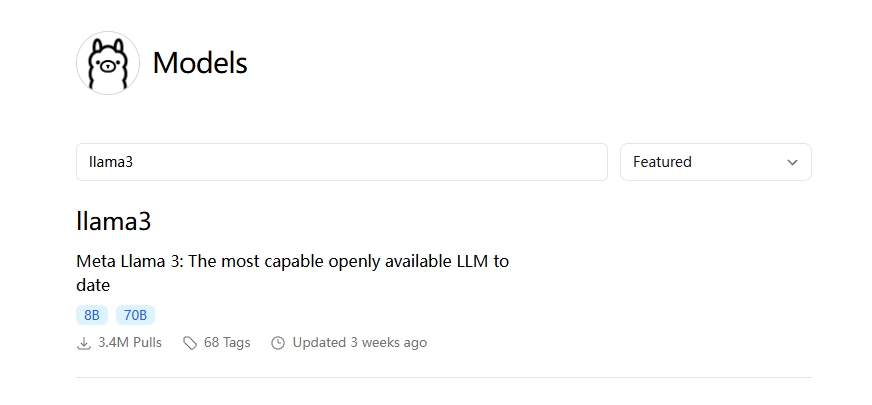
对应模型会有很多详细信息,比如笔者需要的llama:3b,对应的命令也会有提示
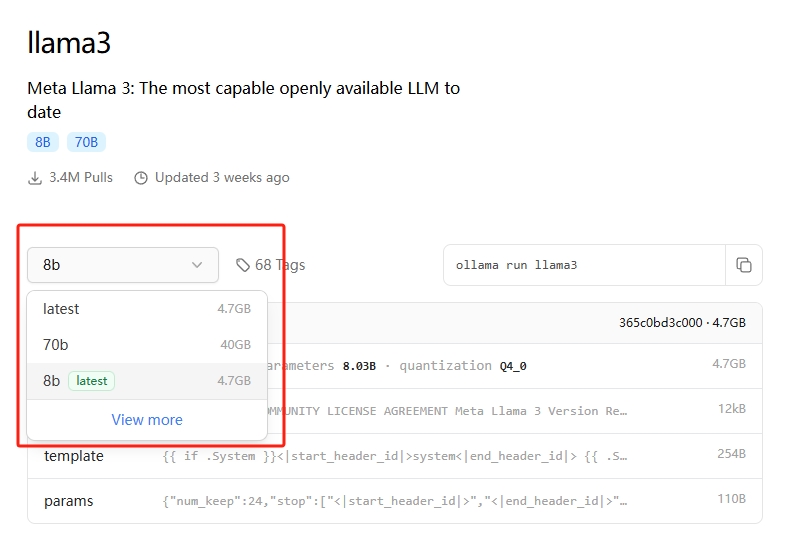
本地pull
Ollama提供了两个命令,一个是ollama pull xxx用来pull对应模型,一个是ollama run xxx用来pull&run对应的模型
笔者这里习惯在新机器上先pull好几个模型然后再使用API直接调用,所以习惯用拆开的run命令
1
ollama run llama3:8b
展开
这里有个小tips,llama3的默认模型是8b,所以ollama run llama3和ollama run llama3:8b都会run 8b的模型
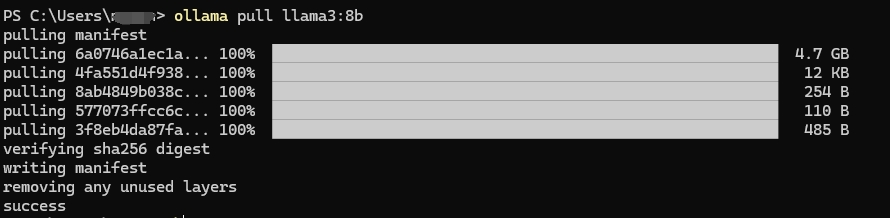
本地run
1
ollama run llama3:8b
展开
这里启动速度取决于硬盘,内存和cpu
笔者这里是7800x3d配7900GRE,执行8b模型的速度还是十分快的:
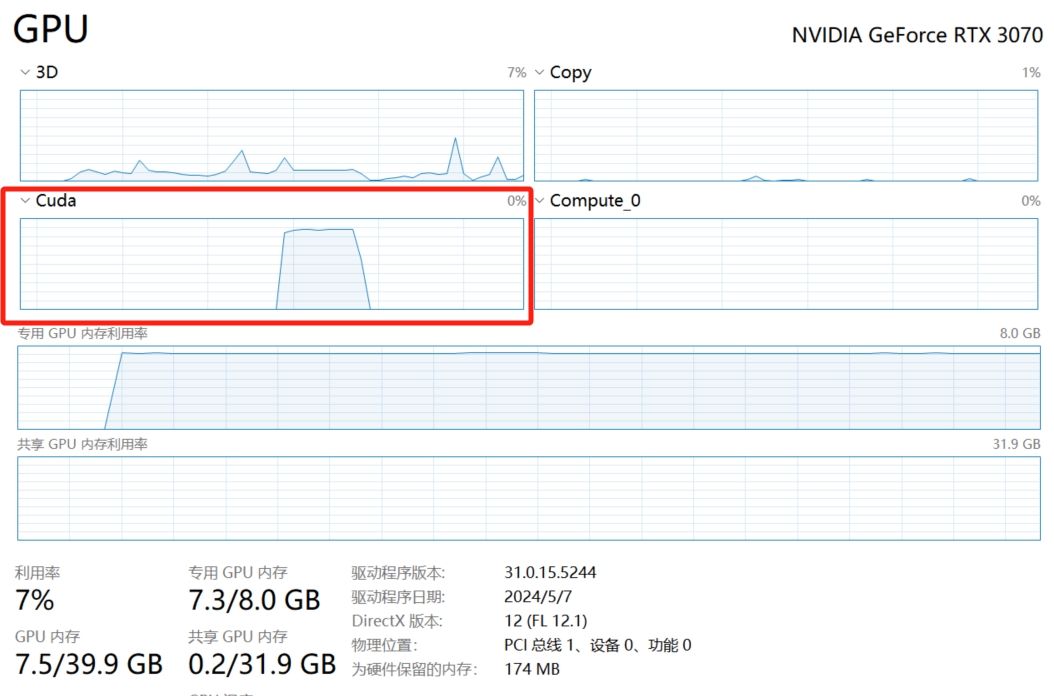
上文提到本地run模型会自动使用显卡算力,这里有个小tips,默认任务管理器的显卡信息显示的利用率并不是对应显卡的算力,如下gif中可以看到其实将Compute 0作为指标更为合适
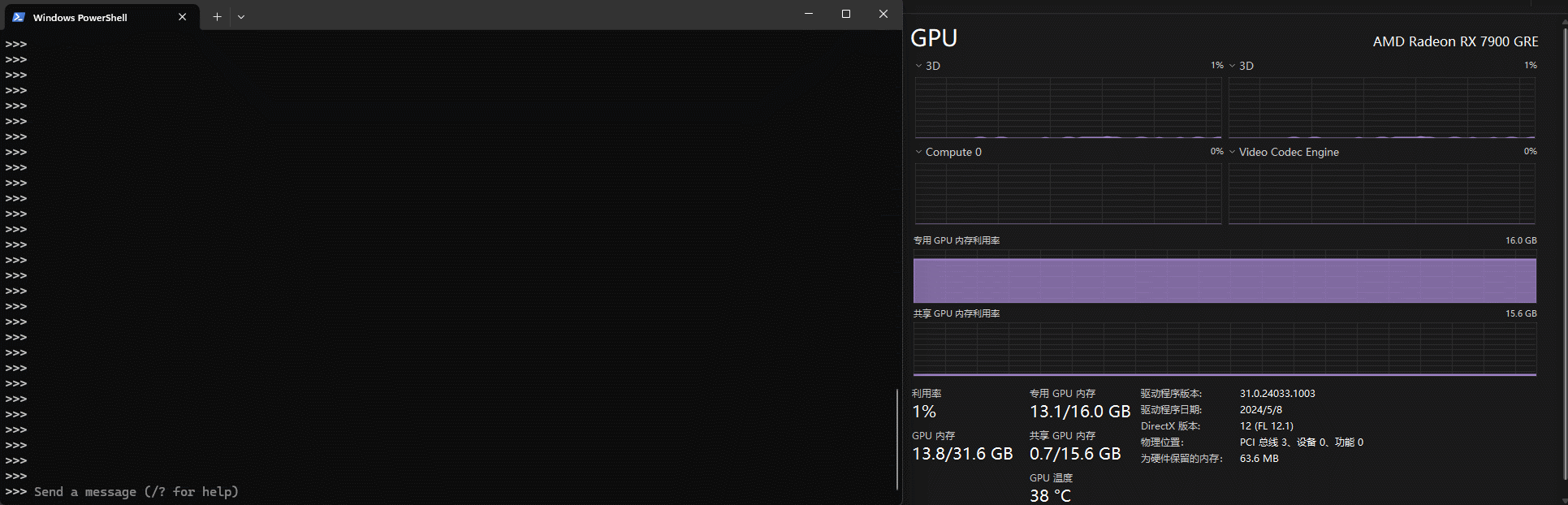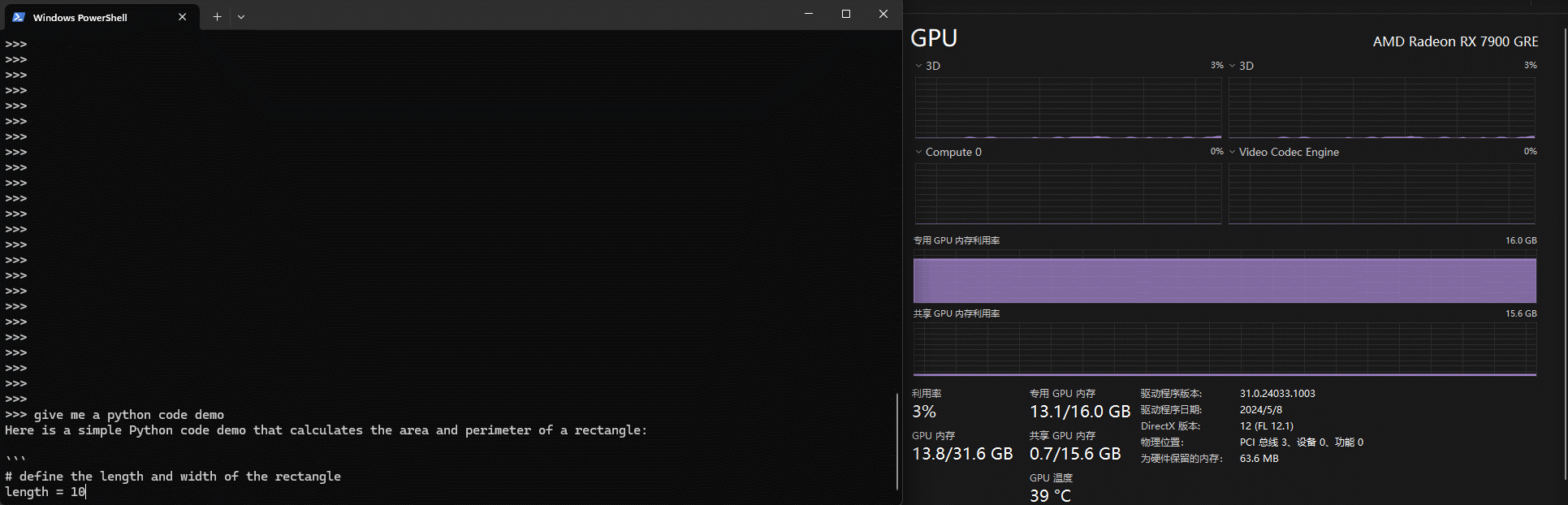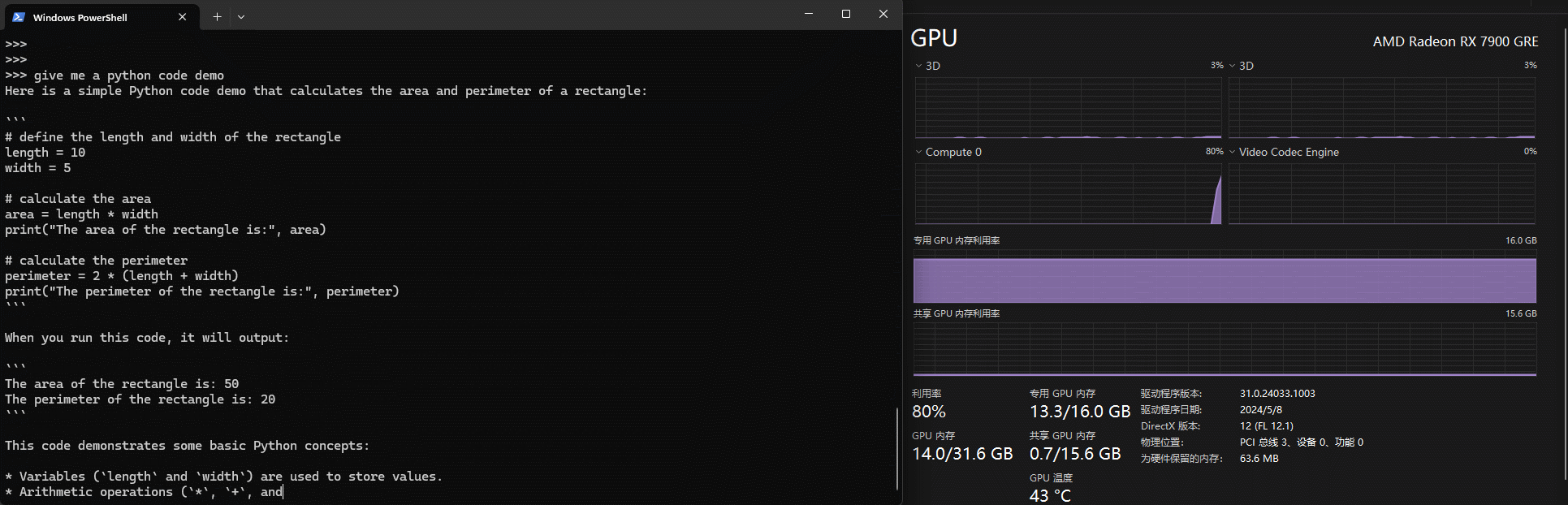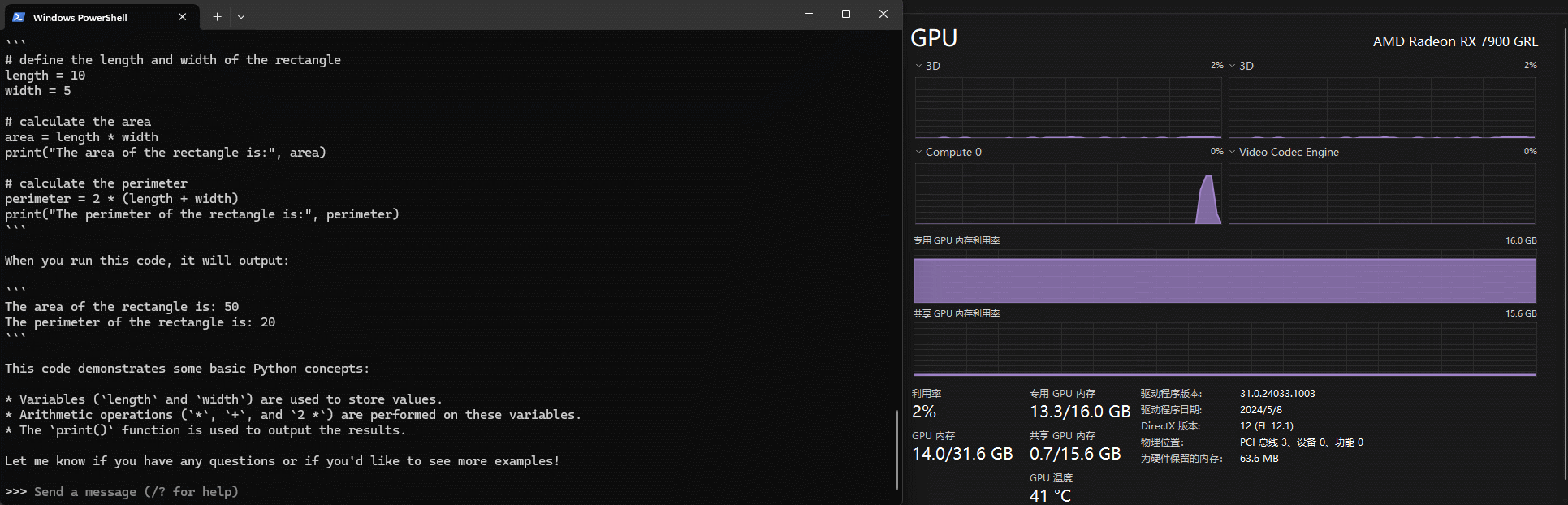
N卡的话观察cuda会更合适一些。
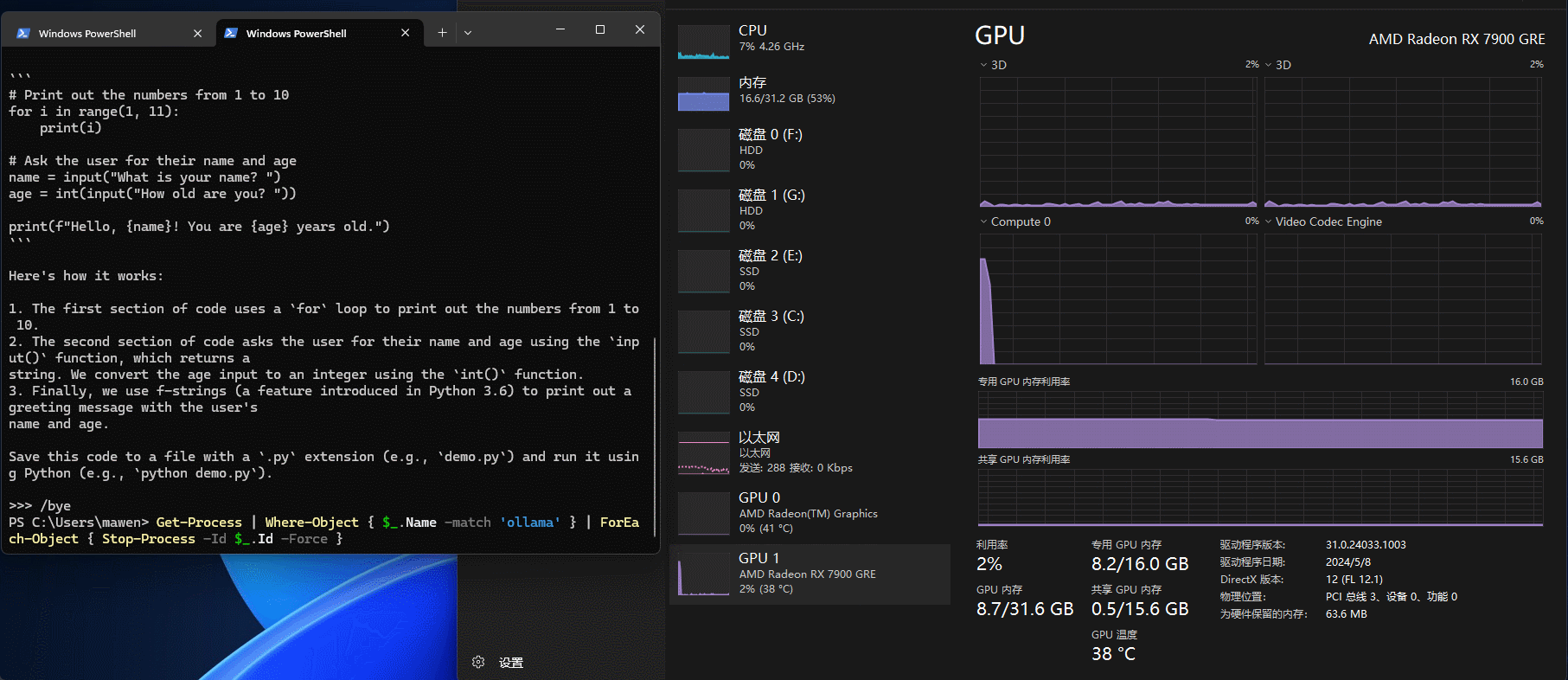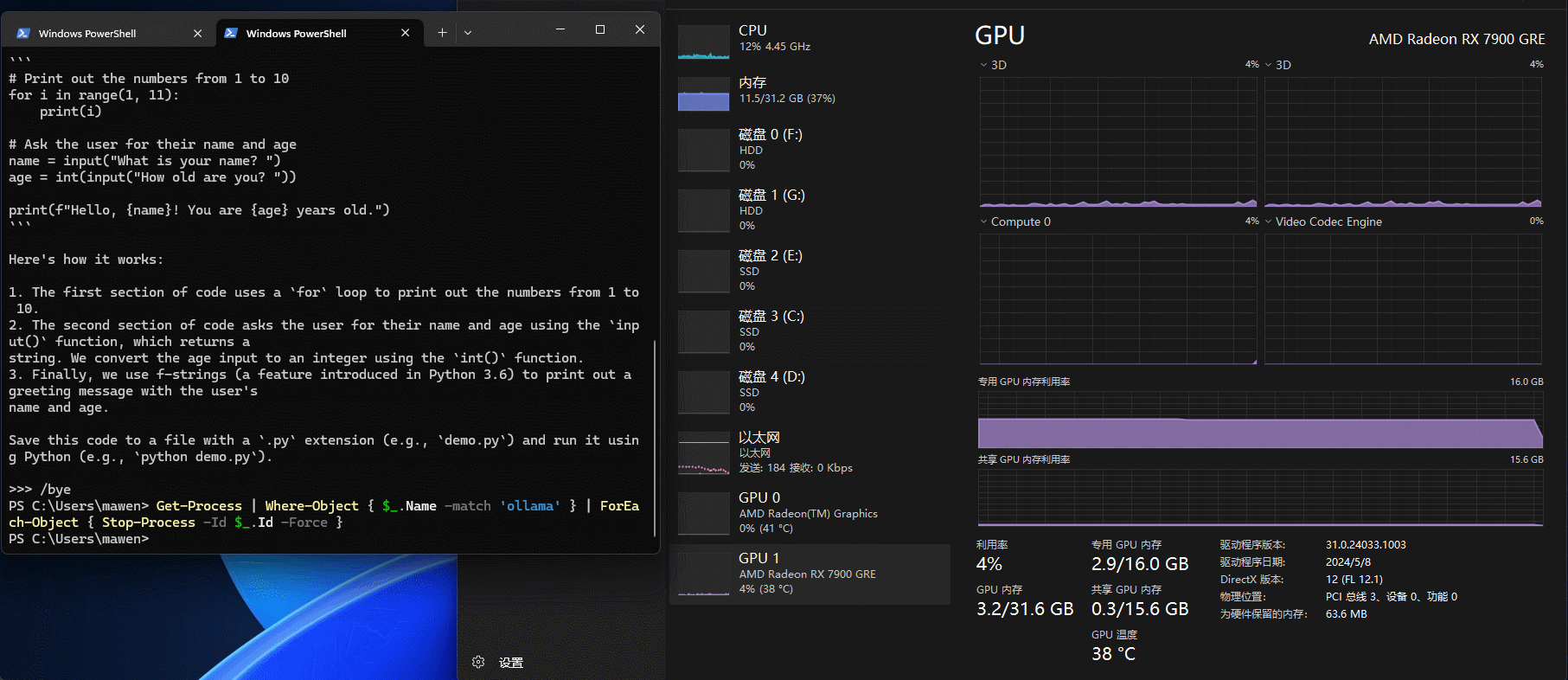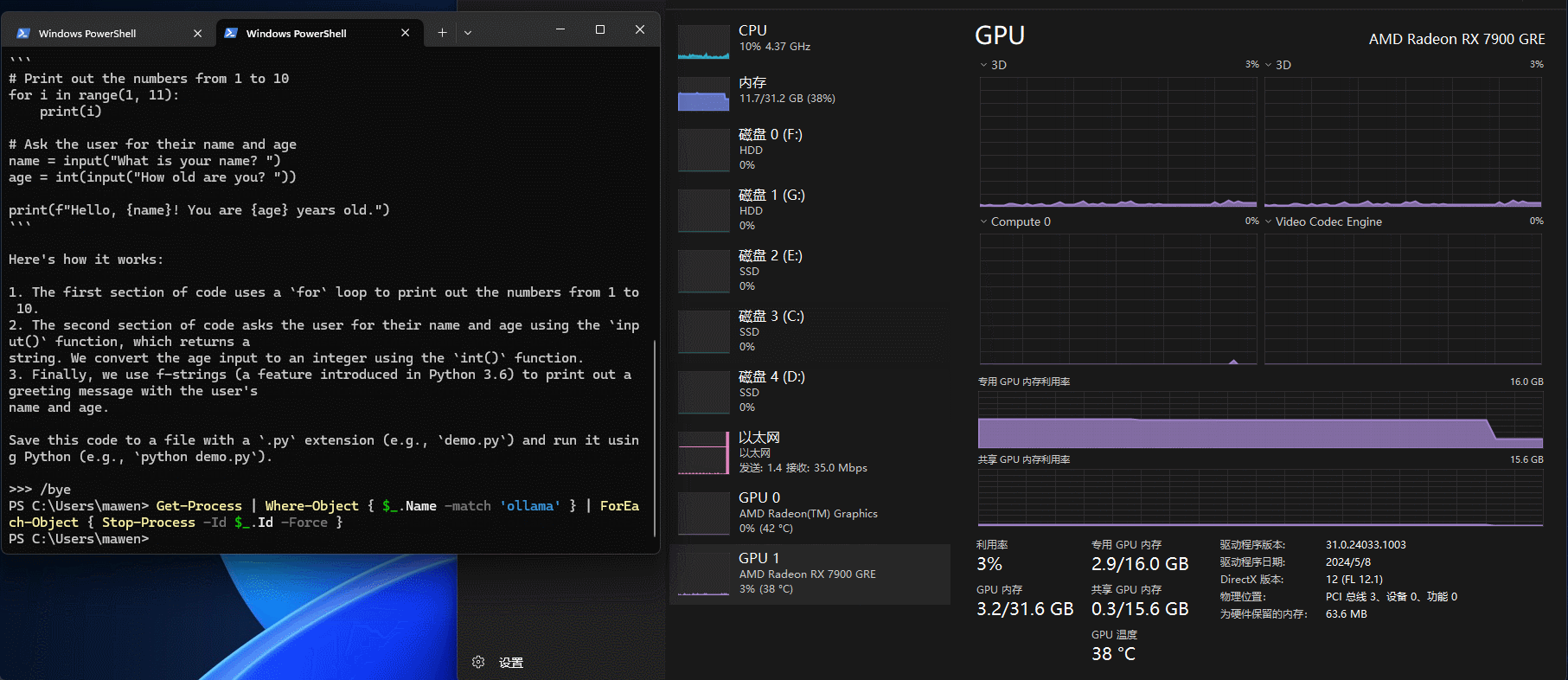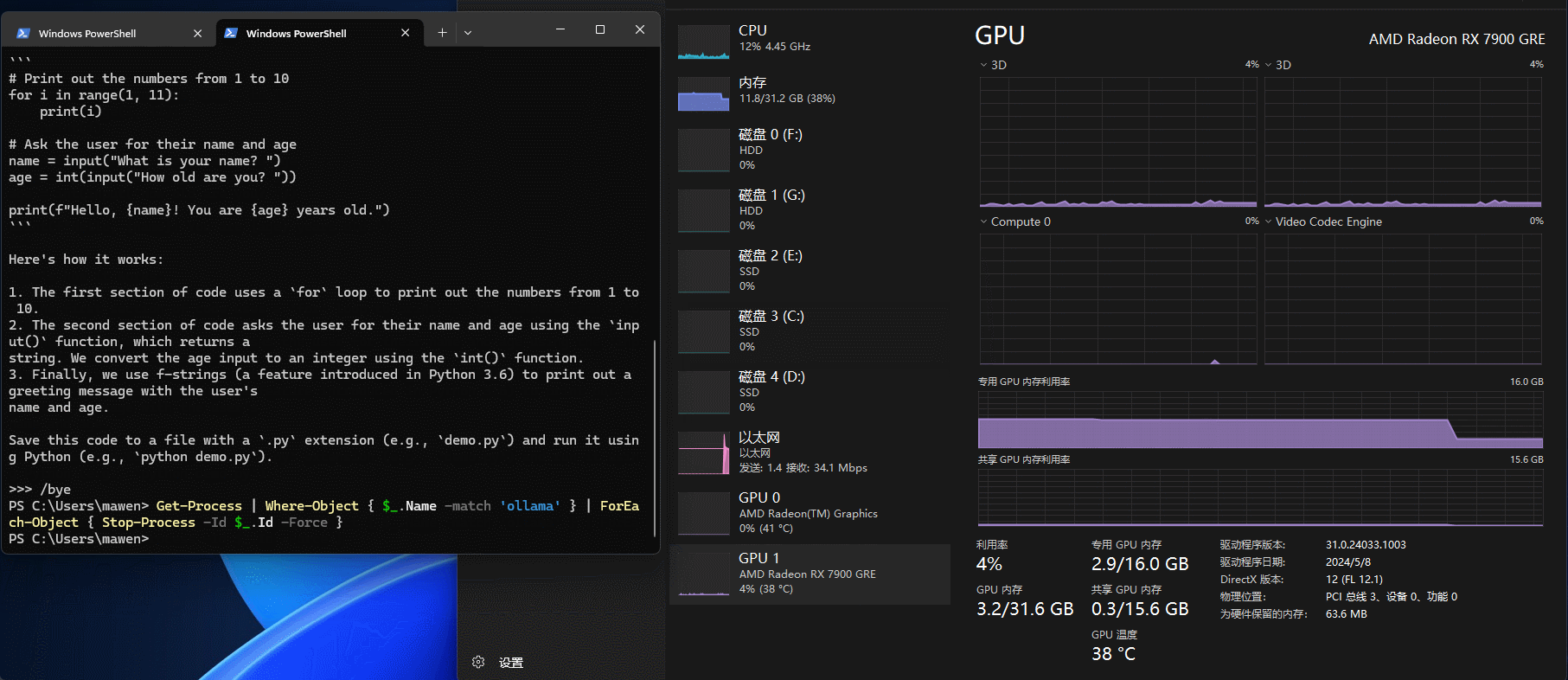
Ollama模型退出
Ollama提供了退出的命令 /bye,但是这个命令只能退出命令行,后台的模型和任务其实都还在
这里上文有提到过,Ollama有个不能退出模型的小bug,如果需要完全退出,需要在任务管理器中杀掉如下几个Ollama进程才行:
1 2 3 4 5 6
映像名称 PID 会话名 会话# 内存使用 ========================= ======== ================ =========== ============ ollama.exe 42004 Console 1 19,528 K ollama app.exe 39268 Console 1 18,204 K ollama.exe 45728 Console 1 147,600 K ollama_llama_server.exe 43844 Console 1 5,201,756 K
展开
或者直接在powershell中执行如下命令:
1
Get-Process | Where-Object { $_.Name -match 'ollama' } | ForEach-Object { Stop-Process -Id $_.Id -Force }展开
杀掉之后如下图所示,会发现之前cpu和gpu占用的内存都会释放掉。
API调用
一般该API主要是提供给一些套壳ChatGPT使用,而且主流的项目也都支持使用Ollama提供的接口,一般都是为了体验,简单使用下就好,这里推荐使用Open WebUI,如果之前有配置过一些套壳ChatGPT项目,建议查看下项目文档对Ollama的直接支持;
LibreChat
这里笔者以LibreChat的配置为例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
custom: # Groq Example - name: "Ollama" apiKey: "ollama" baseURL: "http://127.0.0.1:11434/v1" models: default: [ "llama3:8b", "llama3:70b" ] fetch: false # fetching list of models is not supported titleConvo: true titleModel: "qwen:110b" summarize: false summaryModel: "qwen:110b" forcePrompt: false modelDisplayLabel: "Ollama" addParams: "stop": [ "<|start_header_id|>", "<|end_header_id|>", "<|eot_id|>", "<|reserved_special_token" ]展开
一般每种项目都有自己封装好的接口,不过使用ollama上核心需要提供的也是两种信息,API和模型名称
Open WebUI
以前该项目叫做Ollama WebUI,从名字可以看出就是为了给本地部署的大模型使用的,项目开源,地址为open-webui
这里建议使用Docker进行部署,部署步骤如下:
安装docker与git clone该项目
执行对应docker命令
如果ollama部署在本机,则
1
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
展开
如果ollama部署在其他位置,则
1
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
展开
这里OLLAMA_BASE_URL即部署的主机的地址
运行
完成docker部署后,浏览器打开http://localhost:3000即可访问Open WebUI
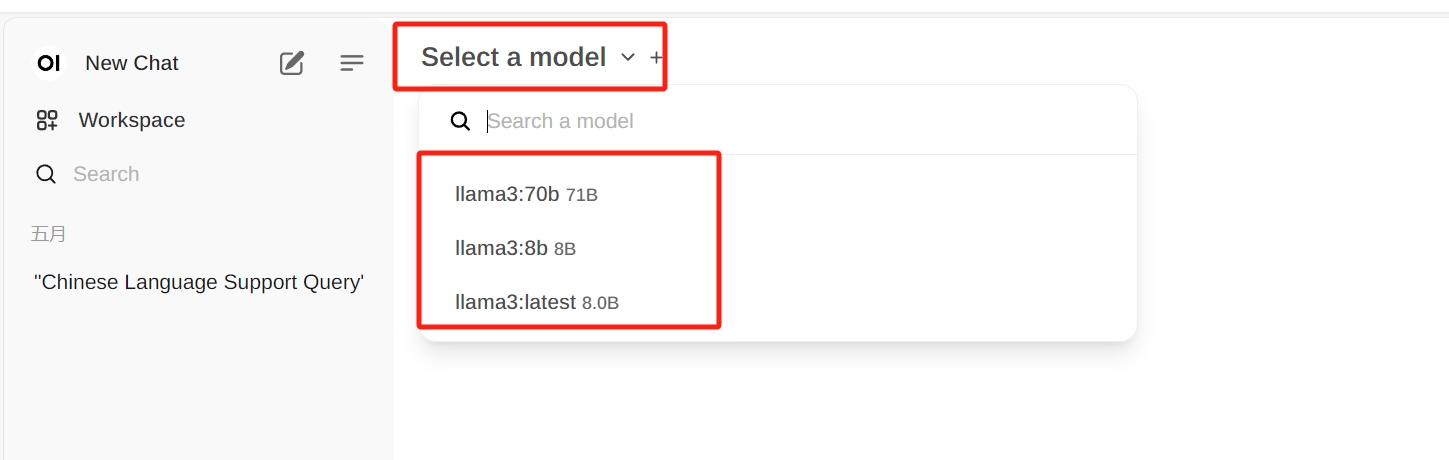
如上图所示,ollama中存在的模型会被自动加载,选择对应模型即可使用

一个运行时的小tips,如果发现无法访问提供的接口,试试是不是ollama的serve没有启动,如果没有的话建议在命令行输入如下:
1
ollama serve &
展开
这样即可访问ollama的服务
Mac 安装
Mac的安装过程实际上与Windows一致,都是从官网下载安装,并运行对应命令行即可,区别在于Mac的配置与Windows不同,Windows支持直接配置环境变量,而Mac则需要修改一些文件达成同样目的
官网下载和运行ollama
配置Mac的环境变量
比较简单的配置是命令行直接输入
1
launchctl setenv OLLAMA_HOST 0.0.0.0:11434
展开
然后重启ollama即可,如果想像传统配置的一样,可以用下面的方法
mac命令行关闭ollama方法:
1
osascript -e 'tell app "Ollama" to quit'
展开
Mac的环境变量是通过修改shell配置文件达成,mac系统有多种shell,从 macOS Catalina 开始 macOS 默认使用 zsh,之前使用的是Bash
检查自己是zsh还是bash
启动终端,输入以下命令:
1
echo $SHELL
展开
/bin/bash 表示使用的是 Bash /bin/zsh 表示使用的是 Zsh
对于 Bash 用户,修改环境变量命令如下:
打开终端
文本编辑器打开 .bash_profile 或 .bashrc 文件,这里笔者习惯使用nano
1
nano ~/.bash_profile
展开
或
1
nano ~/.bashrc
展开
添加环境变量
1
export OLLAMA_HOST="192.168.1.2"
展开
保存并关闭文件
使用以下命令使更改生效:
1
source ~/.bash_profile
展开
或
1
source ~/.bashrc
展开
对于 Zsh 用户
打开终端
文本编辑器打开 .zshrc 文件,这里笔者习惯使用nano
1
nano ~/.zshrc
展开
添加环境变量
1
export OLLAMA_HOST="192.168.1.2"
展开
保存并关闭文件
使用以下命令使更改生效:
1
source ~/.zshrc
展开
不确定自己默认是zsh还是bash,也就是任意shell
打开终端
文本编辑器打开 .profile 文件,这里笔者习惯使用nano
1
nano ~/.profile
展开
添加环境变量
1
export OLLAMA_HOST="192.168.1.2"
展开
保存并关闭文件
使用以下命令使更改生效:
1
source ~/.profile
展开
以上配置完成后,不要忘了启动ollama serve
1
ollama sever &
展开
安装模型与使用
见Windows安装中3与4步骤即可
Linux 安装
官网下载和运行ollama
配置Linux的环境变量
Linux系统与mac中基本一致,见Mac中安装的2步骤即可
安装模型与使用
见Windows安装中3与4步骤即可