LibreChat--钱包积分系统(控制用户tokens使用量)
LibreChat是用户积分系统的,也就是可以控制每个人tokens的使用量。
token相关
如果需要了解LirbeChat中是如何控制每个人tokens的使用量,首先需要了解一些关于token的定义和计算方法,如果已经非常了解,可以跳过该段。
token定义
token,直译为令牌。在大型语言模型(如GPT系列)中,token是文本的基本单位。
理解token对于使用和开发这些模型非常重要。以下是关于token的一些关键点:
基本定义:
Token是文本的最小单位,可以是一个单词、一个单词的一部分、一个标点符号,或者是一个特殊字符。 例如,”Hello, world!” 可能被分成 [“Hello”, “,”, “ “, “world”, “!”] 这几个token。
作用:
输入表示:模型接收输入时,文本被转换成token序列。 输出生成:模型生成文本时,是一个接一个地生成token。 上下文限制:模型有token数量限制(如GPT-3的2048个token),决定了一次可处理的文本长度。
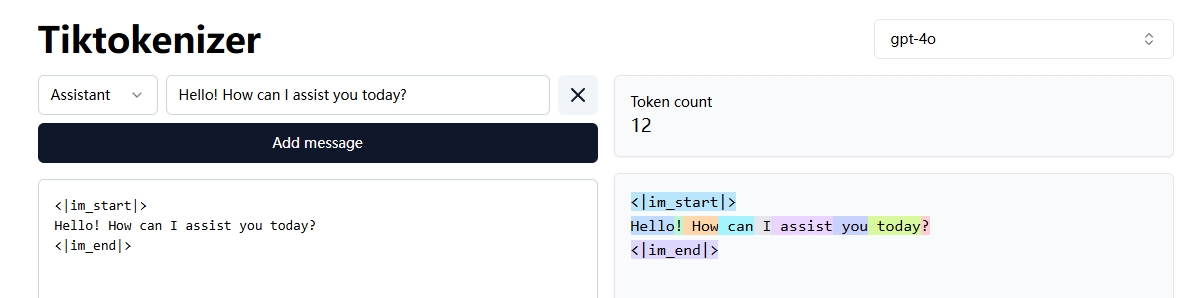
比如笔者做了以下输入:
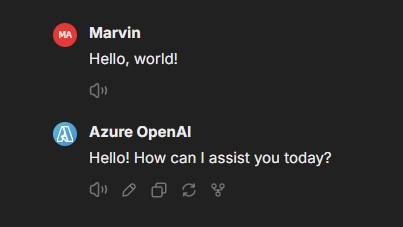
那么输入就是”Hello, world!”,模型输出就是”Hello! How can I assist you today?”
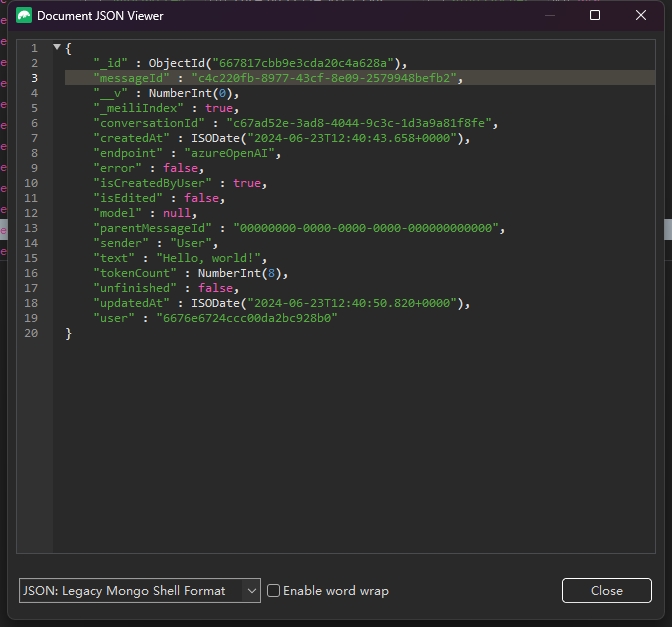
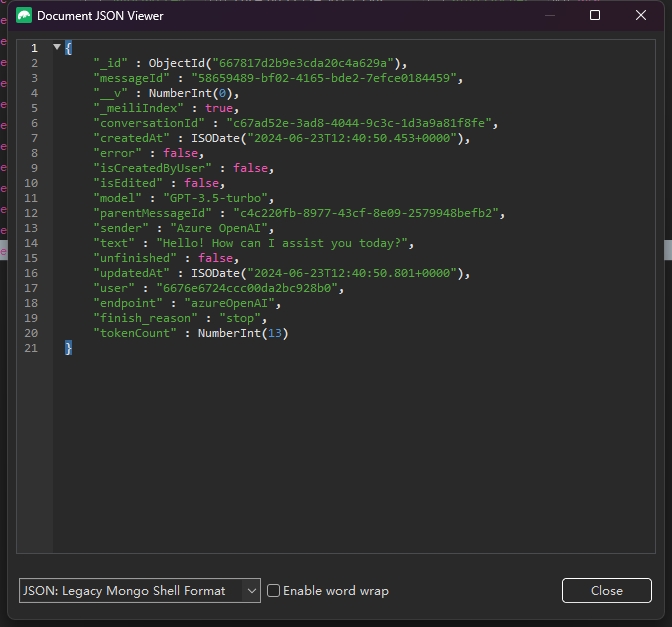
后台可以看到本轮对话的具体信息:
特点:
语言无关:同一个模型可以处理多种语言,因为token是基于统计规律划分的。 非固定长度:英语中,一个token平均对应约4个字符,但这不是固定的。
影响:
计算成本:处理的token数量直接影响计算成本和时间。 模型性能:更多的token通常意味着更好的上下文理解,但也增加了计算负担。
应用考虑:
API使用:许多AI服务按token计费,了解token有助于估算成本。 提示工程:编写高效提示时,需要考虑token的使用。
技术实现:
分词器(Tokenizer)负责将文本转换为token。 不同模型可能使用不同的分词方法,如BPE(Byte Pair Encoding)、WordPiece等。
挑战:
稀有词:某些专业术语或不常见词可能被分割成多个token,影响理解。 跨语言应用:不同语言的token效率可能不同。
理解token概念有助于更好地利用和优化大语言模型,无论是在应用开发、成本管理还是性能优化方面。
token计算
上文定义中提到,AI服务按token计费而不是按照字符数来,而分词器(Tokenizer)是负责将文本转换为token的工具。
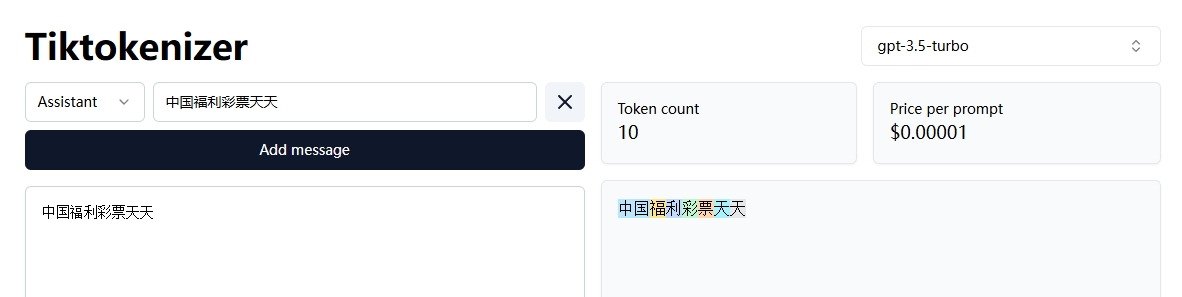
这里关于分词器,每个模型都有不同的分词器,比如gpt-3.5-turbo和gpt-4o,同样的文本经过不同的分词器,结果的token数是不一样的,如下图
这里OpenAI在推出gpt-4o时,为gpt-4o配置了一个全新的分词器,而且该分词器针对非英文语言的句子拆分为更长的词组,也就是说比如这个“中国福利彩票天天”,在之前的分词器中,会有10个token,而在新的分词器中只有2个
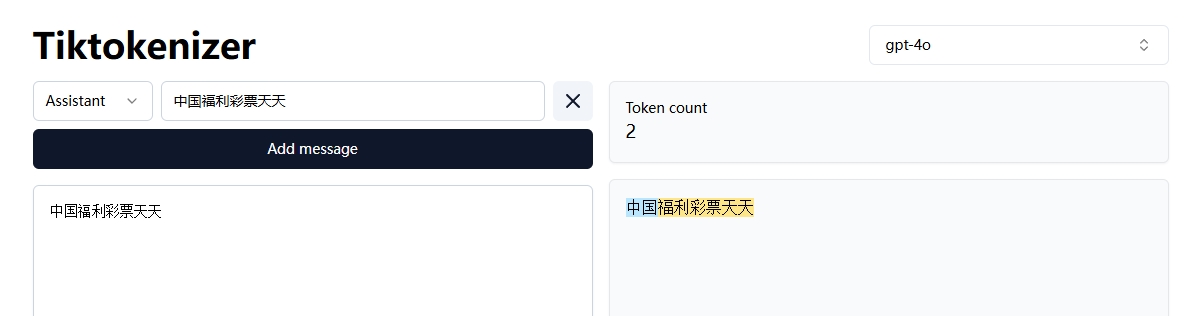
也就是说好的分词器,同样的文本,对应的token少了,而模型计算就是按照token来得,则价格也随之降低了
比如gpt-4和gpt-4o(gpt-3.5和gpt-4用的同样的分词器),这里看起来是价格全面降低了一半,实际上降低的更多

但是分词器只能由具体模型供应商自己决定。
LibreChat钱包积分系统
LibreChat中项目作者设计了一套积分管理系统,这套管理系统能管理每个用户的使用限额,比如给一个用户设定了1000积分,则用户在消耗了1000积分之后,就不能再正常使用了,需要管理员充值才能正常使用,并且项目作者还设计了一套从积分和token之间得转换逻辑,统一了不同token定价的模型,积分始终可以和钱挂钩。
比如假设1刀能换100万积分,再假设100万积分能换gpt-3.5的100万个生成token,同样的,gpt4的1生成token是gpt3.5的20倍,则100万积分只能换5万个生成token
具体计算的细节,首先需要了解LibreChat中实际消耗token具体计算逻辑和包含哪些内容范围,然后再了解项目作者是怎么把积分转换成token的,以及怎么管理和配置用户的积分
LibreChat中token计算逻辑
细心的读者已经发现了,笔者在上文举例中提到的token计算,明明这句”Hello! How can I assist you today?”,只有9个token,为什么数据库中记录了13个,是不是LibreChat在偷摸用我的模型接口。
| 这里是因为OpenAI 的 API 在处理对话时,会添加一些特殊标记,如 < | im_start | > 和 < | im_end | >。这些标记用于标识消息的开始和结束。 |
| 纯文本 “Hello! How can I assist you today?” 确实是 9 个 token,添加 < | im_start | > 和 < | im_end | > 后,总 token 数增加到 13 个。 |
这就是为什么数据库中会出现13个token的原因
| 这里我们用提示输入1和模型返回1来测试,发现LibreChat中数据库都会记录tokenCount为5,也就是会计算< | im_start | > 和 < | im_end | >的4个token |
如下图所示 用户输入1,模型回复一串的数据是: User–tokenCount:5,用户输入1则一共5个token Azure OpenAI–tokenCount:272,模型回复了272个token 总共277个token
用户输入n个字符,模型只回复1的数据是: User–tokenCount:26,用户输入一共26个token Azure OpenAI–tokenCount:5,模型回复1用了5个token 总共31个token

而积分系统中则不同
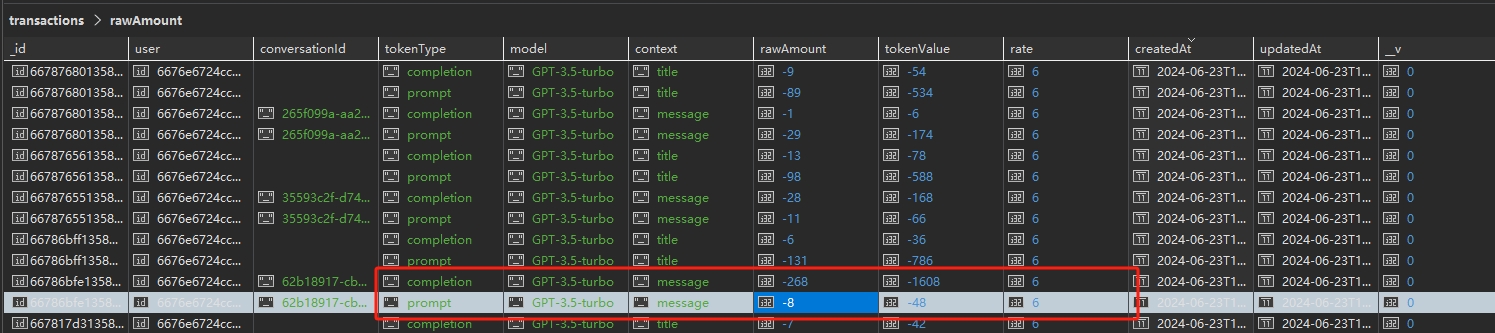
首先是提示输入1和模型回复,如下图所示,积分系统中一共记录了4条数据,分别是
message–prompt:-8,用户输入的1消耗了8个token message–completion:-268,模型回复消耗了268个token title–prompt:-131,预置的生成标题的输入消耗了131个token title–completion:-6,模型回复的标题消耗了6个token 也就是这段对话共消耗了413个token
然后是提示输出n个字符,模型回复1

message–prompt:-29,用户输入的消耗了29个token message–completion:-1,模型回复1消耗了1个token title–prompt:-89,预置的生成标题的输入消耗了89个token title–completion:-9,模型回复的标题消耗了9个token 也就是这段对话共消耗了128个token
这里积分系统细心的用户就会发现,为什么积分系统中记录了这么多,是不是LibreChat在替商家黑我们?
实际上这里是因为大模型的设计,也就是隐形消耗的token了
首先大模型并不是除了我们看到的用户输入1回复了一堆,一共只消耗了277个,实际上还要包括系统角色消耗,标题生成消耗
比如这里提示输入1,则对应的token应该是1,特殊token增加了4个,然后system的提示词又增加了3个,所以用户只输入了1,但是实际消耗是8
而细心的用户又发现,这里生成怎么又算少了,生成的token是272个,怎么积分系统只计算了268个,少算了4个?实际上并不是少算,而是OpenAI并不计算这4个
比如模型回复了1,对应的token应该是1,这里并不用计算特殊Token的4个,也没有其他角色消耗,所以回复1的实际消耗是1
LibreChat中token计算包含范围
项目作者给了一张草图,比较好的覆盖到了计算涉及的范围
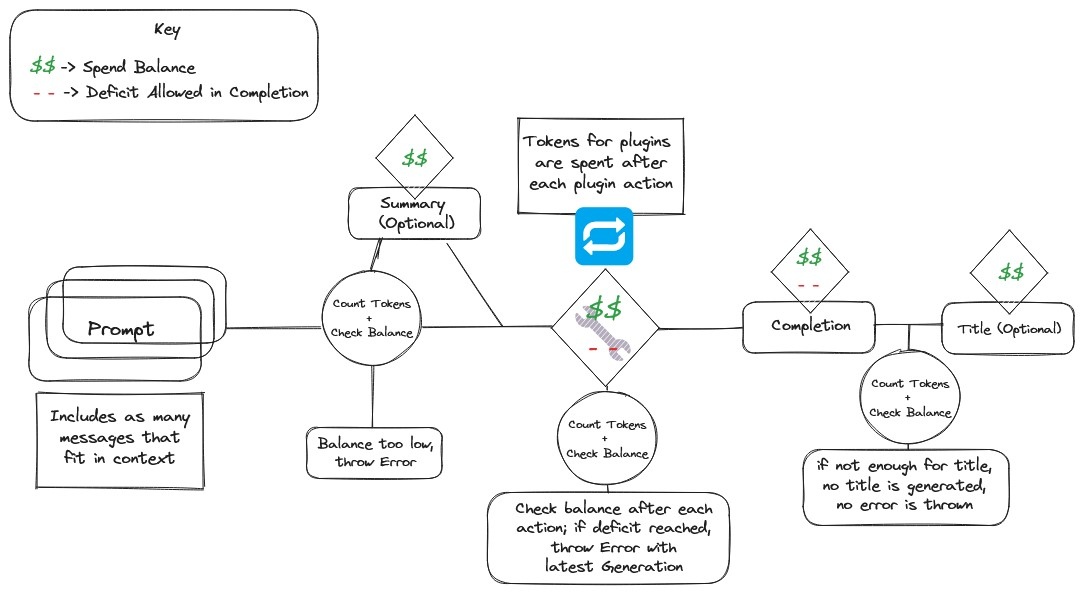
可以先不用看到这张图在计算什么,先看计算覆盖得范围
prompt
输入到大模型的提示词,内容上尽可能包含了上下文相关信息,也就是prompt包含了系统提示信息,上下文信息等;
这里得系统提示信息就像笔者在上文举例中后,输入数字1,token为1,加上特殊token的4个,system的提示词又增加了3个,system就是这里的系统提示信息;
上下文信息笔者上文没有举例,这里假设笔者在prompt为1的那个例子对话下面继续输入prompt 2,则此时的prompt包含了2的token为1个,特殊token的4个,系统提示词,除此之外还有上文笔者输入的1和模型回复的信息,这样模型才会有“记忆”,否则模型就不知道你之前输入过1。
plugins
LibreChat支持插件功能。如果用到了插件,会将插件消耗的token也计算在内;
completion + title
completion指模型在用户输入的prompt下生成的内容。
title是为了获取当前对话的标题,LibreChat会将对话的第一次输入输出信息和一个提示词作为输入获取标题的输出,也就是笔者举例中的数据库中的title部分,包含prompt和completion
以上,即为LibreChat的token计算包含范围
token与钱包积分转换规则
上文中提到,作者设计了一套用户钱包积分管理系统,做到了不论什么模型,都可以用同一个积分管理,这一段我们就来具体解释下项目作者是怎么做到的
积分锚定
项目作者是这样设计积分的,首先作者选定了一个模型的价格,这里他选定了gpt-3.5-turbo的prompt价格,如下图

1106版本的价格是$0.001/1000token,而这个价格刚好是1密尔(密尔:美元弃用单位,1刀=1000密尔)
作者就锚定了这个价格,也就是1000积分可以换取1密尔,0.001刀,可以换取gpt-3.5-turbo-1106版本的prompt是1000token
先记住以上规则,后面会有用到。
积分汇率
作者这里很巧妙得设计了积分,同时关联了美刀和token,也即通过锚定的方式,保证了积分和美刀和token的稳定汇率,这是一个“国际货币”该有的属性,那么在这里汇率是什么?举例如下:
假设笔者这里通过0.01刀换取了10000积分,并且通过gpt-3.5-turbo-1106版本产生如下消耗token的对话:
prompt:1000token completion:3000token
根据那么笔者的积分就需要扣减掉1000+3000*2 = 7000积分,则剩余10000-7000 = 3000积分
上面计算扣减中的第一个1000很好理解,就是prompt的1000token,问题是为什么completion的3000的token要乘2?这个2就是货币汇率。
上文中笔者提到作者锚定了gpt-3.5-turbo-1106版本的prompt价格,是$0.001/1000token,而gpt-3.5-turbo-1106版本的completion价格是$0.002/1000token,也就是completion的token价值是prompt的两倍,也就是prompt与completion的token的汇率是1:2的关系,所以对应消耗token的对话,转换成消耗美刀的对话应该是:
prompt:1000token x $0.001/1000token = $0.001 completion:3000token x $0.002/1000token = $0.006
那么再转换成积分
prompt:1000token x $0.001/1000token = $0.001 = 1000积分 completion:3000token x $0.002/1000token = $0.006 = 6000积分
这就是汇率2的含义。
那么模型如果降价了呢,汇率就做除法
比如现在gpt-3.5-turbo降价到了prompt价格$0.0005/1000token,completion价格$0.0015/1000token,
则汇率就是
prompt汇率 = $0.0005/ $0.001 = 0.5 completion汇率 = $0.0015/ $0.002 * 2 = 1.5,也可以用$0.0015/$0.001=1.5得出汇率1.5
则笔者举例的积分扣减应该是10000.5 + 30001.5 = 5000积分,相对于降价前7000积分少扣了2000积分

对于不同模型也是同样的汇率换算关系,这里再举例gpt-4-32k模型

prompt价格$0.06/1000token,completion价格$0.12/1000token
则对应的汇率分别是 prompt汇率 = $0.06/ $0.001 = 60 completion汇率 = $0.12/ $0.001 = 120
对应的积分消耗扣减就是1000token * 60 + 3000token * 120 = 60000 + 360000 = 420000积分
(价格贵到笔者既定自己的10000积分不够花)
LibreChat配置与管理钱包积分系统
笔者在上文提到了几个关键词,不同模型消耗的token,积分,汇率。
而这三个变量最终是将大模型算力价值,也就是消耗的积分,转换成了美刀,这也就是为什么这个系统叫做钱包积分系统。
而