LibreChat--多平台安装和基础配置
前言
笔者是十分看好LibreChat项目的,其项目思想和现在比较火热的ChatGPT-Next-Web和LobeChat有很大不同,其一开始就有鉴权和后端数据库,这决定了LibreChat的交互体验,尤其是跨设备体验是非常舒适的,这也是笔者在自己家里和公司都选择LibreChat的原因。笔者写这篇文章主要是为了记录部署过程,后续调整时使用。
部署过程
LibreChat的项目文档十分细节,细节到教会你如何更新Docker配置。如下图所示:
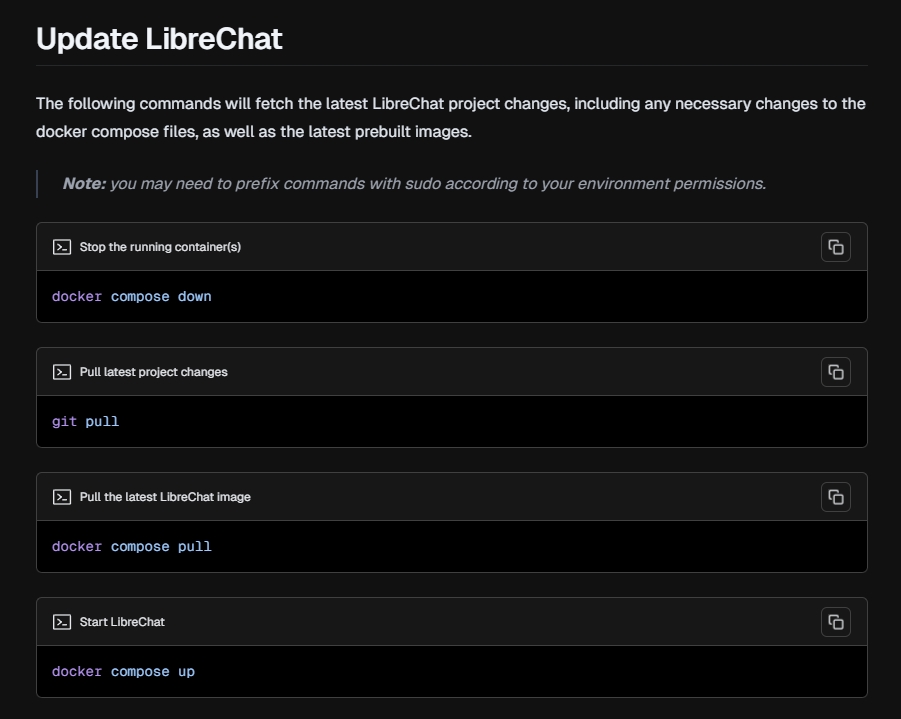
项目文档十分细节是非常难得的,这直接会让用户的部署和维护变得不是那么困难。并且项目支持多种部署方式,这里介绍下两种部署方式,使用Docker部署和使用Windows部署,使用Linux和Mac也大同小异。
不过部署过程还是有点小坑,尤其是第一次部署的,不一定能顺利部署启动成功,下面是笔者自己在Windows使用docker和直接部署的过程,以及踩坑&解决办法
使用Docker部署
Docker的部署十分简便,如果各位部署环境中有长期运行的Docker服务,十分建议选择此种部署方案,性能方面Docker几乎没有损失。其他情况还是建议直接部署比较好。
clone对应项目
使用git clone命令获取到项目代码。如果是长期使用,这里笔者建议下载release版本较为稳定,目前(2024年5月23日)libreChat暂未发布release版本。
1
git clone https://github.com/danny-avila/LibreChat.git
展开
release版本
1
git clone --branch v0.7.2 https://github.com/danny-avila/LibreChat.git
展开
Windows安装docker并启动
docker官网下载并启动即可
配置启动项目
命令行进入1中clone的项目根目录,首先使用cp命令创建env文件,这个相当于项目运行的小配置文件,第一次运行可以先不用管内容,先运行起来再说
1
cp .env.example .env
展开
再运行docker命令启动(执行命令前建议国内的小伙伴配置下docker的国内镜像源aliyun_mirror
1
docker compose up -d
展开
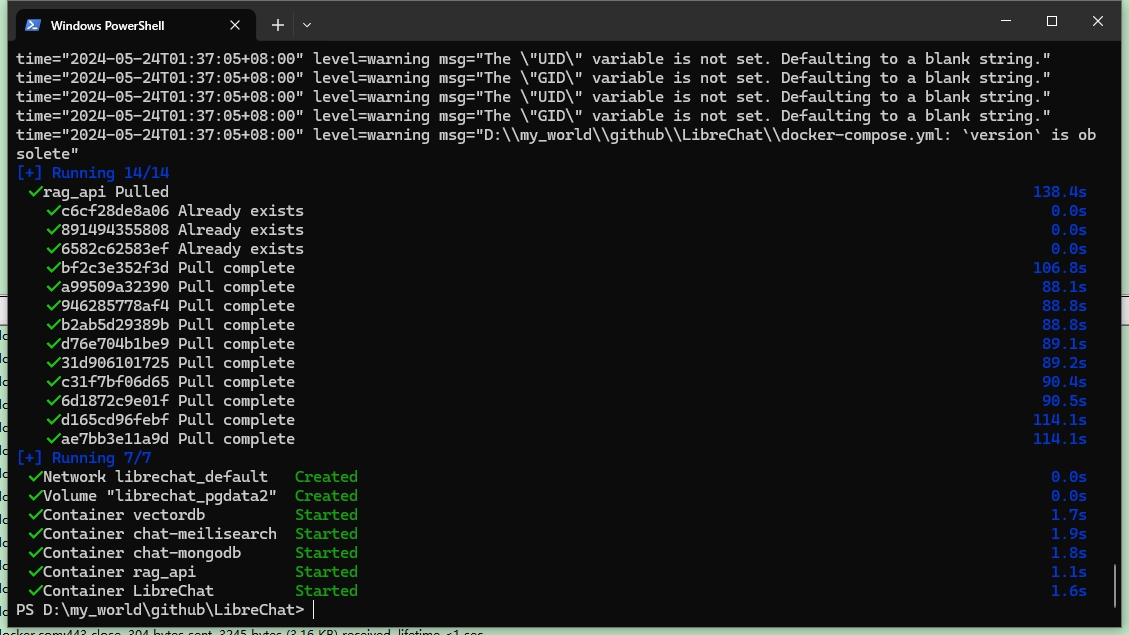
上面的命令会自动拉取所需要的镜像,并创建启动容器,启动运行正常后,因为这里命令带了-d,所以运行正常之后,命令行可以正常执行命令的。
这时候进入http://localhost:3080/ ,正常就会出现相应的注册登录界面
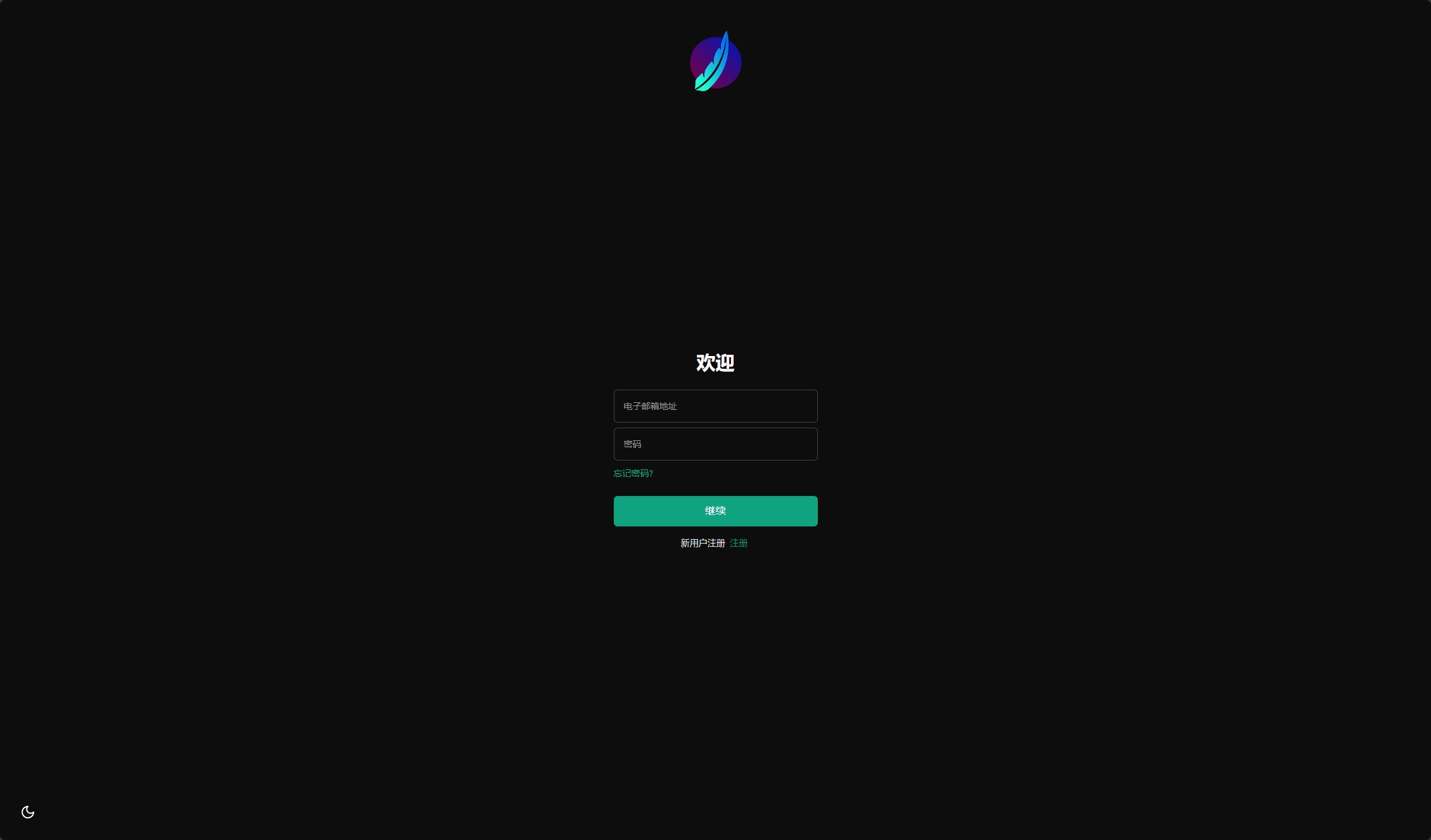

以上是正常使用docker从git clone到可以运行的过程,这时候注册登录,就能在网页中,输入对应得key来设置使用预置的大模型,UI设计几乎和ChatGPT完全一致。
如果需要进一步配置,比如配置默认的模型和key等,就需要修改config文件,笔者这里介绍下两种配置,一种是Azure,一种是笔者本地的llama3,两种方案涵盖了大部分需求:
libreChat配置Azure OpenAI
笔者这里默认大家已经配置好了Azure OpenAI模型部署相关,所以会直接从libreChat的配置写起,项目工程作者也提供了配置的方法说明configuration
首先需要按照作者的步骤,复制粘贴下config文件(好像新版本作者取消了这个步骤)
1
cp librechat.example.yaml librechat.yaml
展开
配置Docker override
这里作者给出了配置的步骤,参考:https://www.librechat.ai/docs/configuration/docker_override
这一步很多人配置的时候漏掉了,会导致librechat.yaml文件失效。
修改librechat.yaml,配置Azure OpenAI
作者给每一个修改都添加了具体的修改说明,比如Azure OpenAI
Azure OpenAI的配置因为有了终结点,部署名和部署模型等,变得非常复杂,这里笔者根据自己日常所需,需要三种模型,gpt3.5,4,o,所以举了下例子:
笔者这里假设Azure OpenAI中配置得到了如下参数(key是我乱敲的):
1 2 3 4 5 6 7 8 9 10 11
终结点1: https://marvin-sweden-central.openai.azure.com/ 密钥: deas90d8f90as8d8f09a8sd0asdfa 部署模型1: gpt-4 部署名: gpt-4-turbo 部署模型2: gpt-35-turbo 部署名: gpt-35-turbo 终结点2: https://marvin-us-north-central.openai.azure.com/ 密钥: jolk122j312jlkj1l2k3jlkjasdf 部署模型1: gpt-4o 部署名: gpt-4o
展开
这里由于Azure OpenAI并不是在所有地区开放所有模型的,所以需要配置多个终结点,比如笔者这里,需要使用gpt3.5和4以及4o,3.5和4部署在瑞典中部,而4o部署在美东,具体部署模型与地区可以参考: 模型摘要表和区域可用性
那么对应的librechat.yaml就需要添加如下的配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
endpoints: azureOpenAI: # Endpoint-level configuration titleModel: "gpt-3.5-turbo" titleMethod: "completion" summarize: true summaryModel: "gpt-4o" plugins: true groups: # Group-level configuration - group: "sweden-central" apiKey: "deas90d8f90as8d8f09a8sd0asdfa" baseURL: "https://${INSTANCE_NAME}.openai.azure.com/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${version}" instanceName: "marvin-sweden-central" models: gpt-3.5-turbo: deploymentName: gpt-35-turbo version: "2024-02-01" gpt-4: deploymentName: gpt-4-turbo version: "2024-02-15-preview" - group: "us-north-central" apiKey: "jolk122j312jlkj1l2k3jlkjasdf" baseURL: "https://${INSTANCE_NAME}.openai.azure.com/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${version}" instanceName: "marvin-us-north-central" models: gpt-4o: deploymentName: gpt-4o version: "2024-02-01"展开
作者的配置为了适配Azure OpenAI的复杂性也非常复杂,配置参数之间也相互有耦合,也不太好理解。这里笔者能省略即省略了,这个应该是能配置2个终结点多个模型的最简化配置了。
下面我分别解释下上述出现的配置是干嘛的
首先是Endpoint-level configuration的配置(azureOpenAI下面的第一层缩进)
titleModel: 配置生成对话中的标题的模型,就是这里
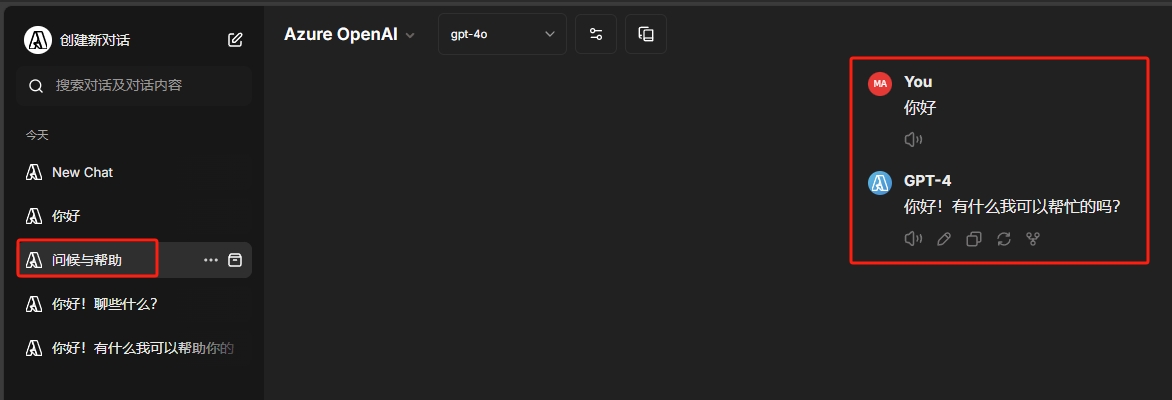 这里可以看出,模型根据对话内容自动总结出了标题,一般不重要,不过还是要有的吧,可以直接设置成模型名,也可以设置成”current_model”
这里可以看出,模型根据对话内容自动总结出了标题,一般不重要,不过还是要有的吧,可以直接设置成模型名,也可以设置成”current_model”titleMethod: 决定titleModel生成的方式,有两种选项,像笔者一样不配置默认是”completion”,还有一种是”functions”,两个的区别作者没有写,不过翻代码可以看到
completion的部分,作者是以system的角色让titleModel的模型生成了标题
functions的部分,作者是用到了langchain那套方法,保底还是completion的,细节不再看了,还是会用到大模型生成的,只是方法不同
所以笔者这里直接默认缺省了
titleConvo: 给所有的Azure模型配置生成标题,默认false,笔者暂时没发现使用场景,因为就配置了3个gpt的,暂时缺省了
summarize: 给所有的Azure模型配置对话摘要,默认false,这个是摘要功能,开启这个可以节省token,建议开启
很多类chatGPT都会有摘要功能,原因是长对话会出现上下文,如果不开启摘要,会将对话原封不动的再次传递给模型,会浪费大量的token,开启后可以摘要后再传递给模型,节省token,建议开启。
summaryModel: 摘要也是需要大模型来做的,所以需要配置摘要的模型,这里也别太省,gpt-4o是个不错的选择
plugins: 插件功能,作者给配置了几个比较常用的插件功能,Google搜索,Azure AI Search之类的,要深入配置的,如果感兴趣可以阅读作者的tools
这里作者没有写明白开启的这个插件是什么,笔者自己理解是这里配置插件为true时,对应插件会使用该大模型,配置为true的话插件这里如下图所示

如果没有配置,默认会是false,默认会使用openai的大模型,需要输入key才能正常使用插件。
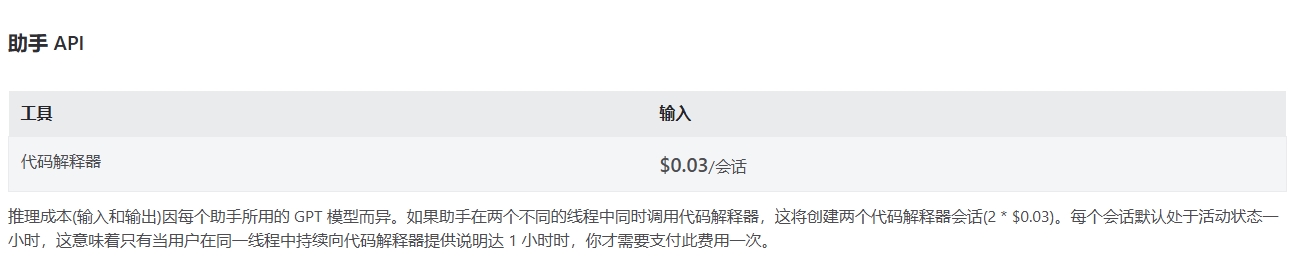
assistants: 这个是设置Azure assistants的,关于assistants可以看微软的文档Azure assistants
笔者个人理解Azure assistants十分没有必要,一般公司内不会将资料拱手给微软,一般个人用户也没有那么多资料需要,而且部分会有额外定价,笔者这里看到定价是0.03刀每次
综上,作者这里在# Endpoint-level configuration的配置如下
1 2 3 4 5
titleModel: "gpt-3.5-turbo" titleMethod: "completion" summarize: true summaryModel: "gpt-4o" plugins: true
展开
然后是# Group-level configuration(groups下面的缩进)
group:不会影响实际功能,只是为了标记每个grop的不同,这里笔者因为每个grop是用了一个Azure地区,于是就使用了Azure的地区名
apiKey:就是密钥
instanceName:作者解释是Name of the Azure OpenAI instance,笔者这里翻代码发现这个instanceName实际上就是Azure的那个终结点前面的一段数据
比如笔者的终结点是https://marvin-sweden-central.openai.azure.com/,那么这个instanceName就是marvin-sweden-central
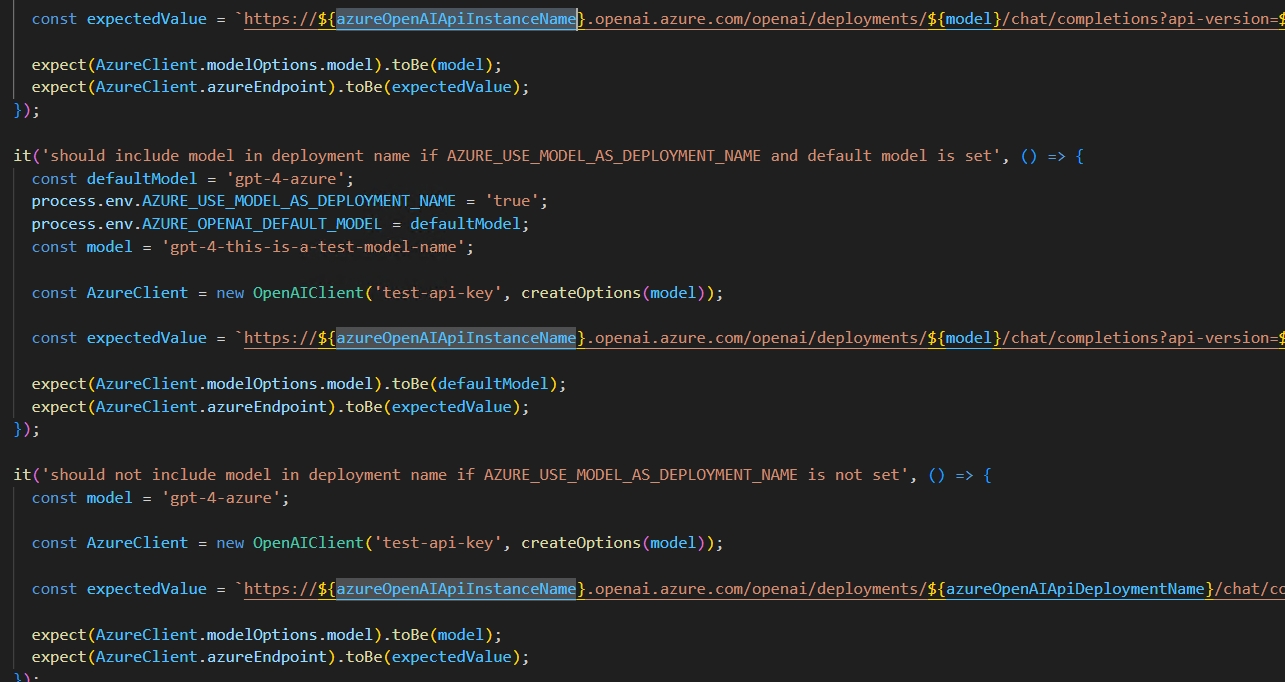
deploymentName:部署模型自己定的名称

version:调用模型用的API版本(注:不是部署模型的版本),这个可以从文档中获取,不过我一般都是直接从部署模型调试的代码中直接抄
进入模型部署-聊天-查看代码,这里就有对应的api版本

- baseURL:建议直接照抄笔者的配置
作者说是可选的,可是笔者多次尝试了不使用而是直接填写其他信息的方式配置,发现不太好用,于是在代码中找到了最终转换成的url,之前很长一段时间Azure在代码中请求的URL如下
1
GPT4V_ENDPOINT = "https://marvin-sweden-central.openai.azure.com/openai/deployments/gpt-4-turbo/chat/completions?api-version=2024-02-15-preview"
展开
笔者尝试了下,结合作者给出的例子,转换成如下的baseURL
1
https://${INSTANCE_NAME}.openai.azure.com/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${version}展开
additionalHeaders:没有找到具体使用场景
serverless:需要设置“Models as a Service”,笔者没有使用场景,也未配置
addParams:其他参数,如max_tokens,temperature配置等,笔者这里使用了默认,各位可以按需配置即可
dropParams:也是模型配置参数相关,如top_p,presence_penalty,presence_penalty等
forcePrompt:forcePrompt 参数的主要作用是简化请求格式,使其更符合某些API的要求,特别是在需要一个单一的文本有效负载的情况下。笔者这里举例说明下
比如笔者这里需要向模型提问天气怎么样,一般的写法是这样的
1 2 3 4 5 6 7
{ "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What's the weather like today?"} ] }展开
当 forcePrompt 参数设置为 true 时,请求将改为使用一个 prompt 参数,包含所有消息的内容,如下所示:
1 2 3 4
{ "prompt": "System: You are a helpful assistant.\nUser: What's the weather like today?" }展开
这种方式在某些情况下更为简洁,也更容易与一些需要单一文本输入的API兼容,这里笔者不需要,所以缺省该参数。
最后是Model Configuration:
- Model Identifier:这个即模型名,是什么模型就配置成什么即可,会显示在用户选择模型的时候,也会作为参数名
- Model Configuration:这个参数开始,即是Model Identifier的下一级,注意缩进。这个参数有Boolean也有obj,建议像笔者一样配置成obj即可,不用简化配置以免更麻烦
- deploymentName:这里设置成Azure OpenAI的模型自定义的部署名即可
- version:API名字,参照笔者上面Group-level configuration层的说明即可
以上即是Azure OpenAI配置librechat.yaml的参数全解析,建议直接按照笔者的配置复制粘贴并修改自己的参数值即可,作者这里为了更好的拟合Azure OpenAI也是下了一番功夫。
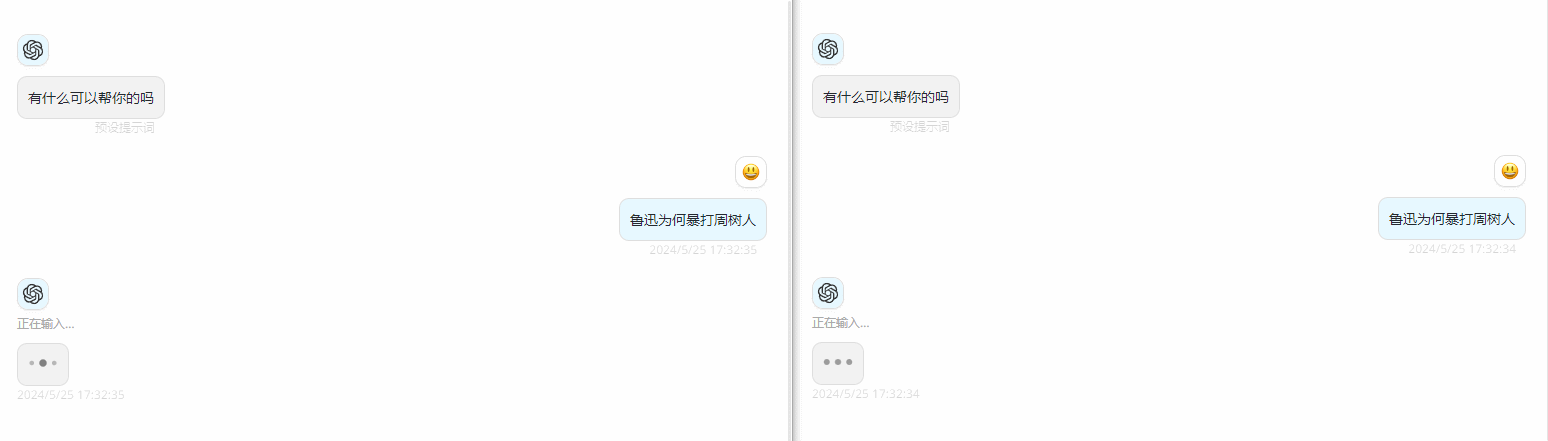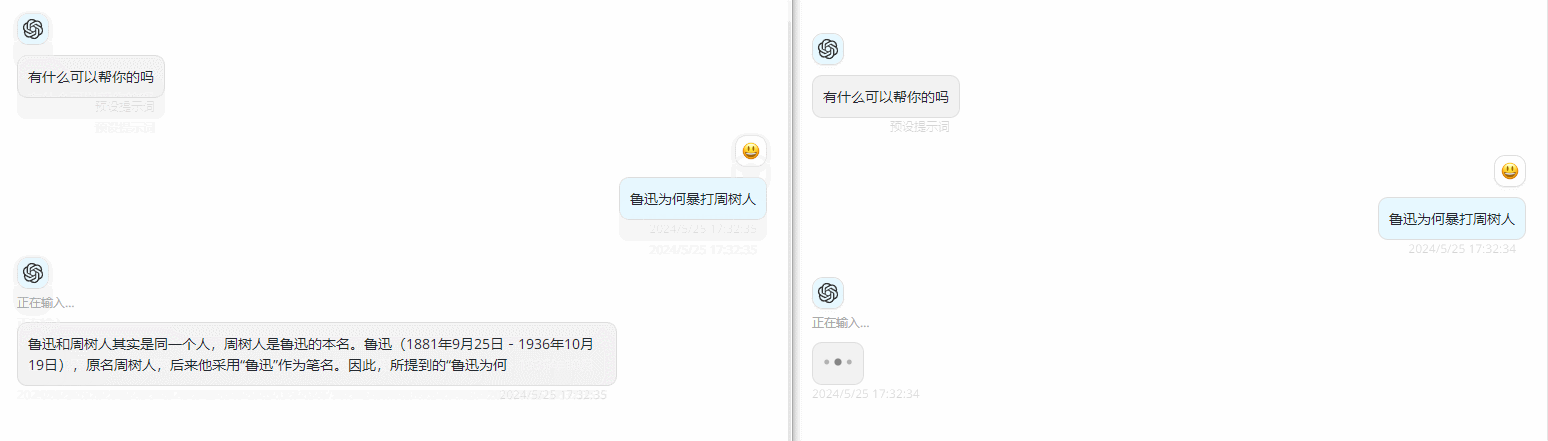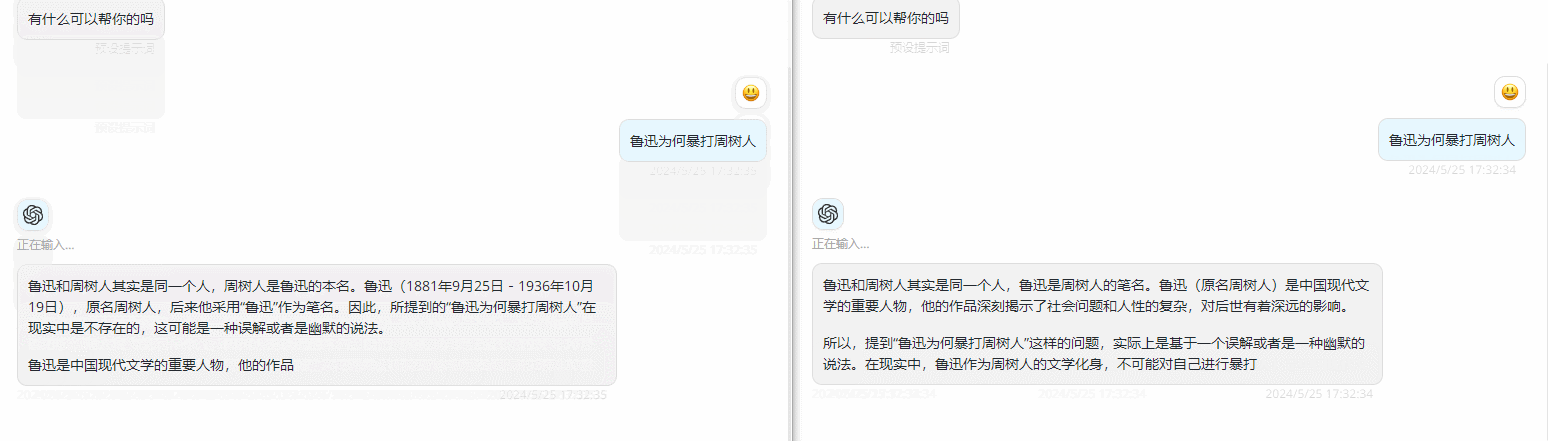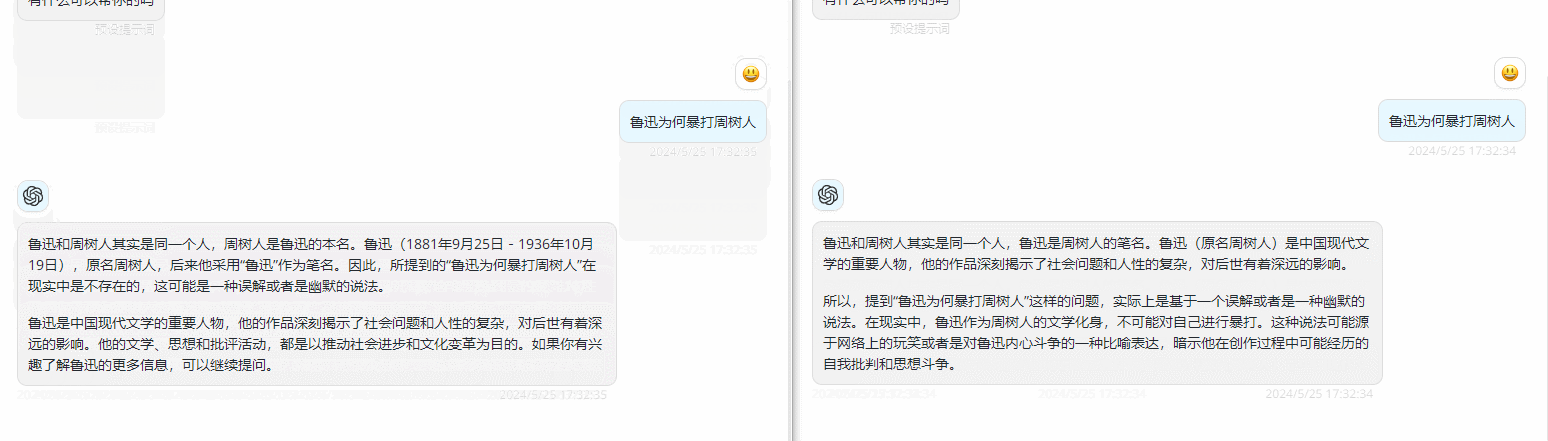
如果配置完成使用时发现没有类似ChatGPT使用时的那种打字机的感觉,或者称为流输出,是因为Azure默认配置了内容筛选器,需要特殊配置下才会有打字机效果,可以参考下笔者的另外一篇文章做配置:
下图效果左为特殊配置后,右为默认配置
libreChat配置llama3
llama3的配置比较简单,但是也有坑点。
首先作者也已经发布更新匹配了llama3模型的适配,也给出了具体的配置

上面的配置,除了缩进问题,作者给的baseURL,是考虑到大部分人是使用的docker,所以url是http://host.docker.internal,这里如果部署的机器也是运行笔记本的同机器,则不用修改。
如果是局域网的两台机器,则上述配置也无法使用,是需要配置成ip地址的
比如笔者运行ollama的机器ip地址是192.168.50.153
则笔者的baseURL应该是
1
http://192.168.50.153:11434/v1/
展开
这里如果使用的是Windows配置的ollama,记得配置环境变量,一个是为了网络访问,默认是只能本机访问的,另一个是模型保存的位置,如果你不希望自己的C盘很快红了,最好还是配置一下。

所以笔者最终的librechat.yaml配置是
1 2 3 4 5 6 7 8 9 10 11 12 13
endpoints: custom: - name: "Ollama" apiKey: "ollama" baseURL: "http://192.168.50.153:11434/v1/" models: default: [ "llama3" ] fetch: false # fetching list of models is not supported titleConvo: true titleModel: "current_model" modelDisplayLabel: "Ollama"展开

千万注意缩进问题
Docker部署配置问题:
页面右键刷新后跳转到登录界面
这个问题可能是作者cookie没有配置好,导致会在非部署机器上登录后刷新网页直接跳转到登录页面的问题。
23年已经有人给作者提了相关问题,作者给了一种临时的解决办法,但是截止目前(2024年5月27日)正式部署还是有此种问题。

所以需要做如下操作
- 进入项目根目录,cp一个
1
cp docker-compose.override.yml.example docker-compose.override.yml
展开
- docker-compose.override.yml添加如下内容
1 2 3
services: api: command: npm run backend:dev展开
保存后重新运行下就好
- 进入项目根目录,cp一个
配置了librechat.yaml但是未生效
这个问题也是因为Docker找不到librechat.yaml导致的,细心的话会发现运行中就会报错这个:
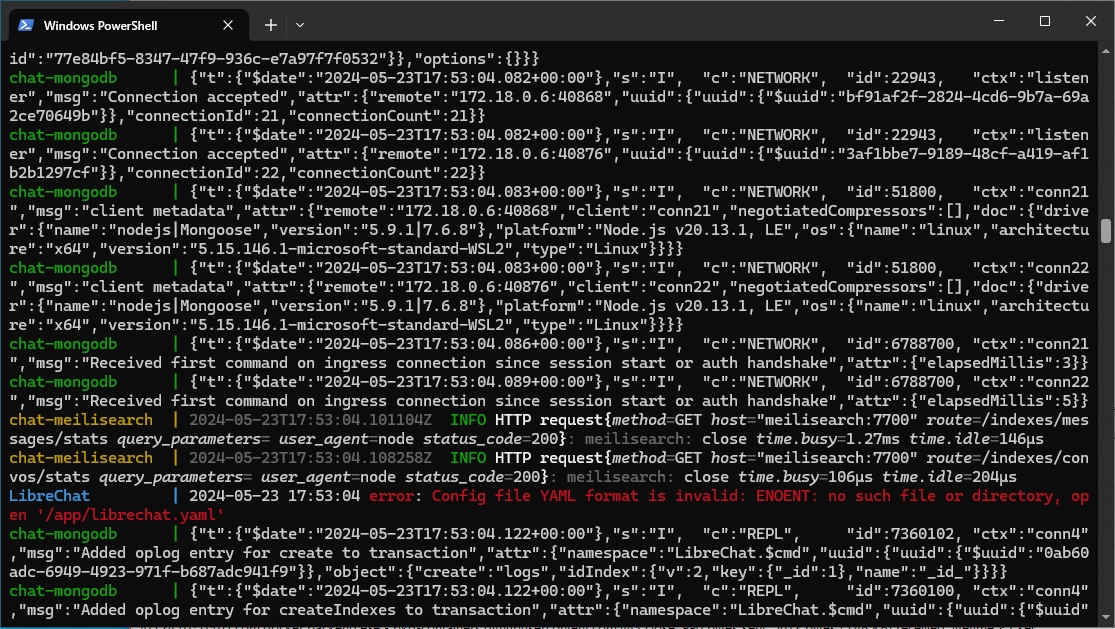
这个问题也是需要修改docker-compose.override.yml来控制,最好不要直接修改docker-compose.yml
如果已经有docker-compose.override.yml文件,就不用执行下面复制这一步,没有得话需要执行下
进入项目根目录,cp一个
1
cp docker-compose.override.yml.example docker-compose.override.yml
展开
确认根目录中有docker-compose.override.yml后,找到api的位置添加一行,如下
1 2 3 4
services: api: volumes: - ./librechat.yaml:/app/librechat.yaml展开
保存后重新运行下就好
直接部署在Windows
如果生产环境不支持使用docker,那就需要直接部署在机器上,这点作者也想到了,所以有第二种办法,直接部署
clone对应项目
使用git clone命令获取到项目代码。如果是长期使用,这里笔者建议下载release版本较为稳定,目前(2024年5月23日)libreChat暂未发布release版本。
1
git clone https://github.com/danny-avila/LibreChat.git
展开
release版本
1
git clone --branch v0.7.2 https://github.com/danny-avila/LibreChat.git
展开
安装npm
前往官网按照步骤要求安装即可
1
Node.js 18+: https://nodejs.org/en/download
展开
安装mongodb
之前有讲过,该项目是为数不多的使用到数据库记录数据的项目,这里有用到mongodb也是直接去官网安装即可。
1
https://www.mongodb.com/try/download/community-kubernetes-operator
展开
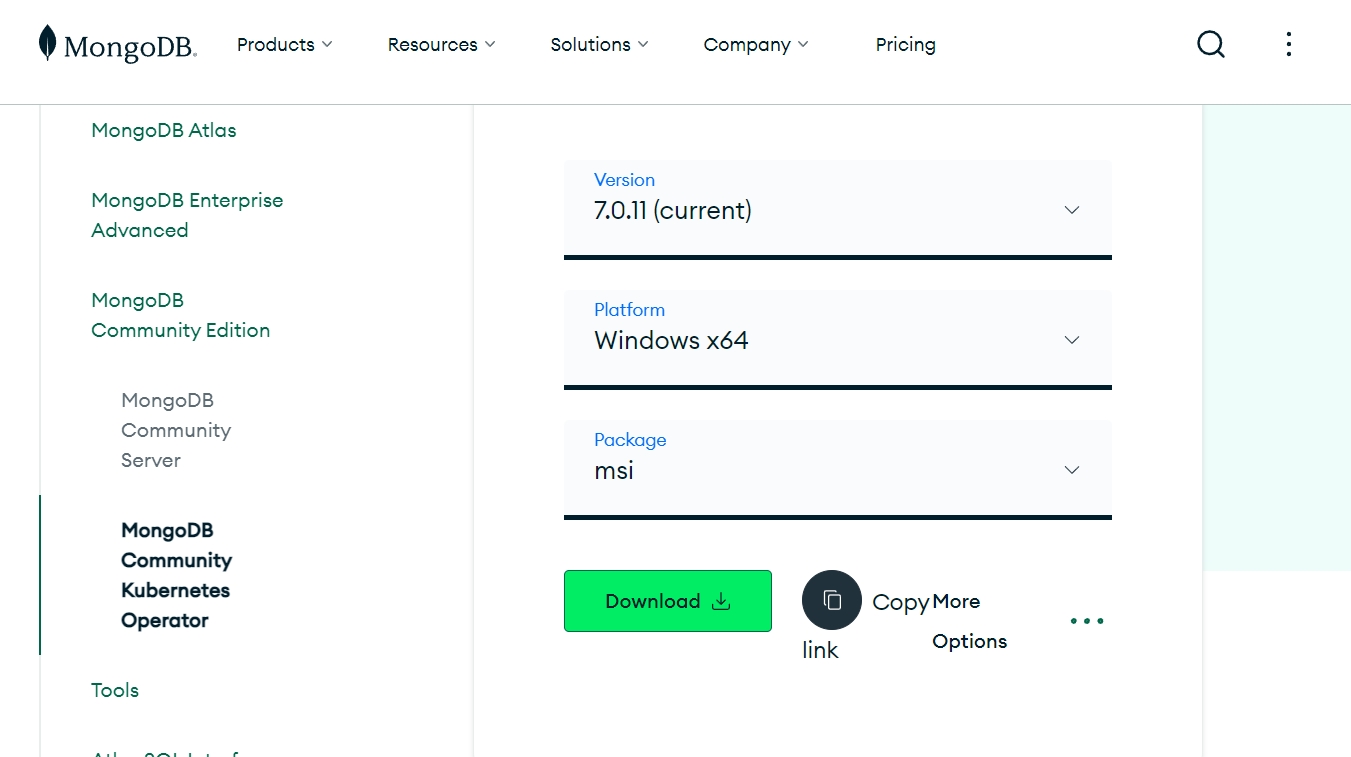
默认配置安装好之后,浏览器中输入localhost:27017,正常会出现如下信息:
1
It looks like you are trying to access MongoDB over HTTP on the native driver port.
展开
如果后续有经常使用数据库的地方,建议再安装一个可视化的数据库管理工具,这里建议安装mongodb自带的工具和robot3t
安装完成后,需要配置下mongodb,这里建议配置下IP和端口:
Windows的配置文件一般在C:\Program Files\MongoDB\Server\7.0\bin目录下的mongod.cfg文件
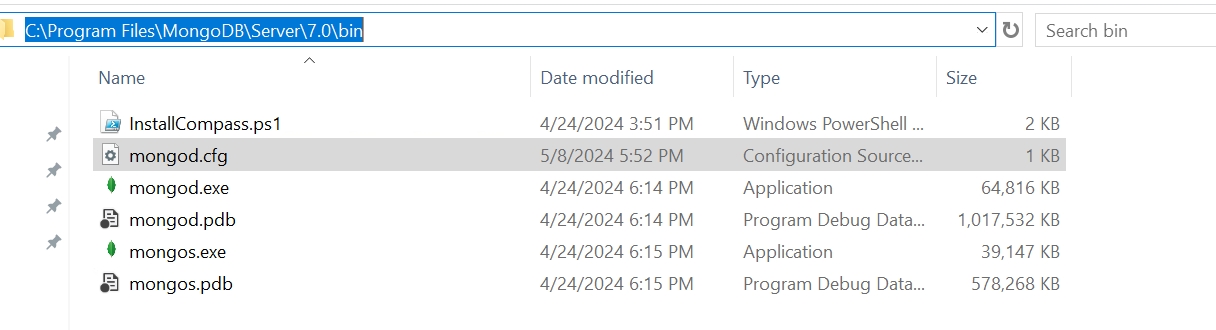
这里需要配置下bindip,默认应该是127.0.0.1,改成0.0.0.0就可以局域网其他机器访问了
修改.env
配置完mongodb后需要修改项目中.env中mongodb的地址到自己刚刚配置的数据库中,默认是127.0.0.1,如果项目部署在和数据库一起的地方则不用修改
build项目
逐步输入以下命令
1 2 3
npm ci npm run frontend npm run backend
展开
如果npm失败,概率是因为网络问题,使用以下三条命令,设置下镜像和超时时间,清理下缓存:
1 2 3
npm config set registry https://registry.npmmirror.com npm config set fetch-timeout 600000 npm cache clean --force
展开
再执行应该就没有问题了
访问http://localhost:3080/
更新代码
如果运行后需要修改或者更新代码,可以更新代码后再执行build项目的三行指令,嫌弃麻烦可以在项目根目录写一个bat, 内容如下:
1 2 3 4 5 6 7 8 9
@echo off echo Running npm ci... CALL npm ci echo Running npm run frontend... CALL npm run frontend echo Running npm run backend... npm run backend:dev pause
展开
以上两种是最基础的部署办法,也就是能启动,更深入的细节可以结合笔者自己使用的部署&管理配置来看
安装部署方式选择:
笔者使用了docker快速验证了配置相关内容和配置调整,正式环境中笔者并没有使用docker来,虽然docker并不会影响性能相关,主要是笔者对于使用docker并不太熟练,为了在正式环境中更好的控制,笔者更偏向于在正式环境中直接部署的方式来使用。
所以部署环境笔者使用了npm,也就是直接部署的方式安装,但是笔者更推荐一般用户使用docker部署。
配置librechat.yaml
这里需要在工程根目录打开一个cmd,并执行一下命令根据作者提供的模板创建librechat.yaml
1
cp librechat.example.yaml librechat.yaml
展开
模型配置:
由于LibreChat是国外的工程,暂时(2024年6月11日)还不支持国内的模型接口,笔者这里也暂时没有使用国内模型API的需求,所以只配置了OpenAI和Ollama两种模型:
OpenAI
可以参考笔者的部署模板:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
endpoints: azureOpenAI: # Endpoint-level configuration titleModel: "GPT-3.5-turbo" titleMethod: "completion" summarize: true summaryModel: "GPT-3.5-turbo" plugins: true groups: # Group-level configuration - group: "xxxxxx-sweden-central" apiKey: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" baseURL: "https://${INSTANCE_NAME}.openai.azure.com/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${version}" instanceName: "xxxxxx-sweden-central" models: GPT-3.5-turbo: deploymentName: gpt-35-turbo version: "2024-02-01" GPT-4: deploymentName: gpt-4-turbo version: "2024-02-15-preview" - group: "xxxxxx-us-north-central" apiKey: "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # baseURL: "https://xxxxxx-us-north-central.openai.azure.com/" baseURL: "https://${INSTANCE_NAME}.openai.azure.com/openai/deployments/${DEPLOYMENT_NAME}/chat/completions?api-version=${version}" instanceName: "xxxxxx-us-north-central" models: GPT-4o: deploymentName: gpt-4o version: "2024-02-01"展开
一般修改下apiKey,instanceName,deploymentName即可使用
Ollama
Ollama是在本地部署的大模型,所以需要先部署好本地的Ollama和对应模型,再在endpoints下一层级如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
custom: # Groq Example - name: "Ollama" apiKey: "ollama" baseURL: "http://xx.xx.xxx.xxx:11434/v1" models: default: [ "qwen:110b", "llama3:70b" ] fetch: false # fetching list of models is not supported titleConvo: true titleModel: "qwen:110b" summarize: false summaryModel: "qwen:110b" forcePrompt: false modelDisplayLabel: "Ollama" addParams: "stop": [ "<|start_header_id|>", "<|end_header_id|>", "<|eot_id|>", "<|reserved_special_token" ]展开
一般修改下模型名称和本地部署的ip地址即可
自定义隐私政策和服务政策
配置这里的跳转链接

笔者这里配置成自己的blog链接了
1 2 3 4 5 6 7 8 9 10 11
# Custom interface configuration interface: # Privacy policy settings privacyPolicy: externalUrl: 'https://winxuan.github.io/plan/' openNewTab: true # Terms of service termsOfService: externalUrl: 'https://winxuan.github.io/plan/' openNewTab: true
展开
配置.env
这里需要在工程根目录打开一个cmd,并执行一下命令根据作者提供的模板创建.env
1
cp .env.example .env
展开
配置mongodb
由于项目需要使用到mongodb数据库,安装完成数据库或者有现成的数据库,需要配置下对应的数据库链接
1
MONGO_URI=mongodb://用户名:密码@ip地址:27017/LibreChat?authSource=admin
展开
一般修改下用户名密码和ip地址就好
配置项目ip地址
项目默认是本地的ip地址,如果其他机器需要访问,可能会出现无法访问的问题,配置下对应的几个ip地址即可
1 2 3
HOST= DOMAIN_CLIENT= DOMAIN_SERVER=
展开
屏蔽不需要AI产品
作者默认是展示所有支持的AI产品,也就是我们默认启动后,左上角下拉框显示的AI能力,如果只想展示几种,则可以编辑如下字段:
找到被默认注释的:
1
# ENDPOINTS=openAI,assistants,azureOpenAI,bingAI,google,gptPlugins,anthropic
展开
解开注释,并将后面支持的AI修改成自己想要的,比如笔者希望有Azure,Ollama和plugin
则对应的ENDPOINTS配置如下:
1
ENDPOINTS=azureOpenAI,gptPlugins,ollama
展开
上述配置也会影响到显示顺序,比如笔者这里的配置即显示如下顺序
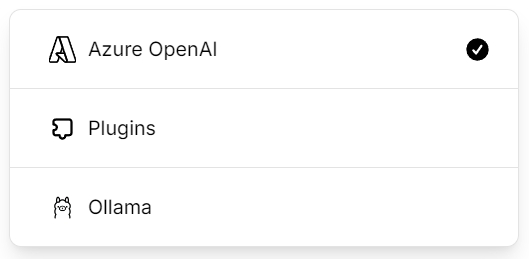
配置邮箱
之所以要配置邮箱相关,是因为作者提供了用户重置密码的能力,重置密码需要向用户邮箱发送一封修改密码的邮件,如果这里不配置会导致任何人只要知道邮箱就能重置对应的密码。

建议使用gmail,作者这里也给出配置的具体方法了
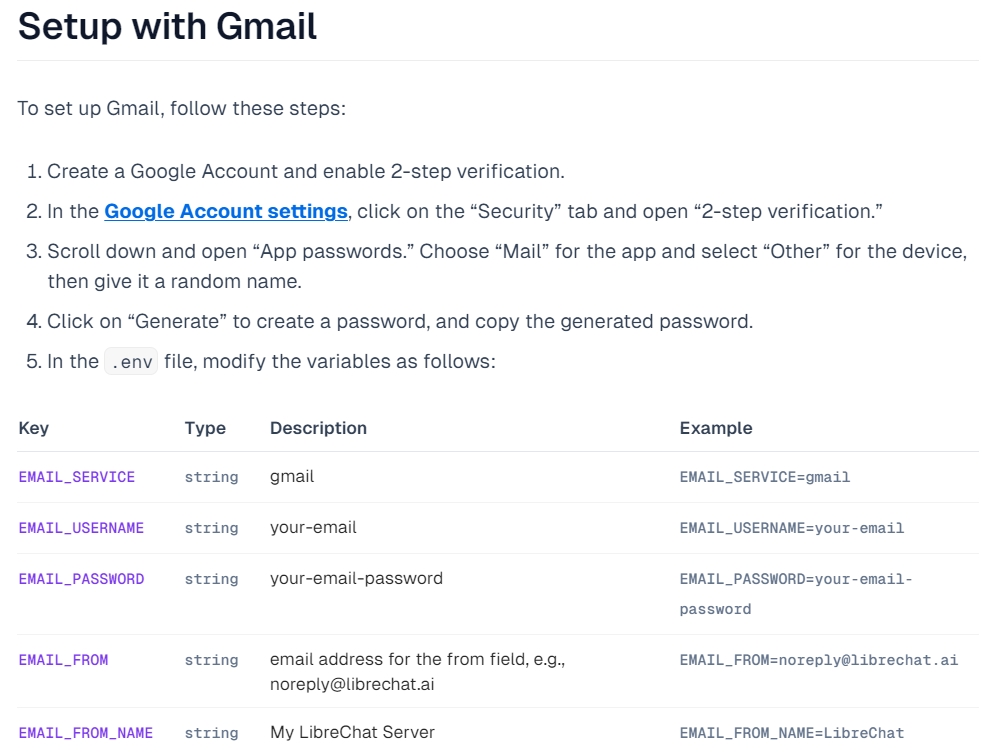
笔者这里配置完成后如下:

尝试下重置密码,邮箱会收到对应的邮件:

软件名修改
如果需要更换email内容中的LibreChat,根据如下代码可以看出,需要再env中配置appname
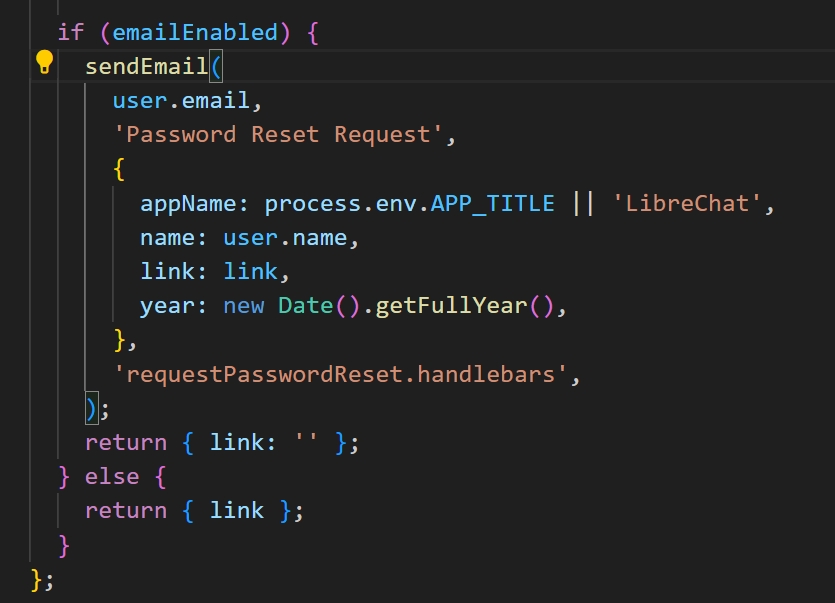
1 2 3
APP_TITLE=LibreChat # CUSTOM_FOOTER="My custom footer" HELP_AND_FAQ_URL=https://librechat.ai
展开
对应可以修改为
1 2 3
APP_TITLE=AIChat CUSTOM_FOOTER="Footer" HELP_AND_FAQ_URL=https://winxuan.github.io
展开
这里修改之后,不仅仅可以修改email中信息,对应的浏览器打开时的标题等也会被更改
会被修改为
如果想修改的比较彻底,对应的index也可以将其修改掉

部署在Linux(树莓派)
笔者在家里有树莓派长期运行,所以部署在树莓派上是一个非常好的选择。
update
1 2
sudo apt update sudo apt upgrade
展开
使用树莓派的默认仓库安装
1
sudo apt-get install nodejs npm
展开
验证安装
1 2
node -v npm -v
展开

如果发现版本过低,比如这里node显示版本是 12.22.12,则后续安装可能失败,

出现这个问题,建议执行以下操作
移除旧版本
1
sudo apt remove nodejs
展开
添加NodeSource仓库
1
curl -fsSL https://deb.nodesource.com/setup_lts.x | sudo -E bash -
展开
安装新版本
1
sudo apt install -y nodejs
展开
验证版本
1
node -v
展开

准备好.env文件和librechat.yaml
配置参数见Windows安装中的配置,这里不区分系统
mongdb
笔者这里的mogodb已经有现成可用的,没有再安装新的,如果需要在Linux中安装mongodb,按照以下步骤进行:
更新
1
sudo apt update
展开
安装
1
apt install -y mongodb-org
展开
配置
1 2 3
sudo nano /etc/mongod.conf #将bindIp修改为局域网ip,比如0.0.0.0,这样才能局域网访问 sudo chown -R mongodb:mongodb /data/mongodb/ #mongodb是使用mongodb用户启动的需要改变其归属 sudo service mongod start #启动命令
展开
连接的话建议使用robot3t或者mongodb官网自带的,看个人使用习惯
build项目
逐步输入以下命令
1 2 3
npm ci npm run frontend npm run backend
展开
如果npm失败,概率是因为网络问题,使用以下三条命令,设置下镜像和超时时间,清理下缓存:
1 2 3
npm config set registry https://registry.npmmirror.com npm config set fetch-timeout 600000 npm cache clean --force
展开
再执行应该就没有问题了
如果你有配置一些vpn,比如笔者这里有配置socks5的,就可以全局使用vpn
- 使用 npm config 设置代理:
1 2
npm config set proxy socks5://192.168.50.113:1080 npm config set https-proxy socks5://192.168.50.113:1080
展开
设置完成后,你可以验证设置:
1 2
npm config get proxy npm config get https-proxy
展开
不想使用,删除对应配置即可
1 2
npm config delete proxy npm config delete https-proxy
展开
- 使用 npm config 设置代理:
访问http://树莓派IP地址:3080/
启动用脚本
如果觉得每次都需要输入三个命令去启动,嫌麻烦可以写一个sh脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33
#!/bin/bash # 设置错误处理 set -e # 定义日志函数 log() { echo "[$(date '+%Y-%m-%d %H:%M:%S')] $1" } # 切换到项目目录 # 注意:替换 /path/to/your/project 为你的实际项目路径 cd /home/pi/github/LibreChat/ # 执行 npm ci log "开始执行 npm ci" npm ci log "npm ci 执行完成" # 执行 npm run frontend log "开始执行 npm run frontend" npm run frontend log "npm run frontend 执行完成" # 执行 npm run backend 并在后台运行 log "开始执行 npm run backend(后台运行)" nohup npm run backend:dev > output.log 2>&1 & log "npm run backend 已在后台启动" # 等待一段时间,确保后台进程已经启动 sleep 10 log "所有命令执行完毕"
展开
停止运行
笔者暂时没有找到更好的办法,一般是直接杀掉所有node
1
killall node
展开