如何调用GPT API
引言
GPT API通过其先进的自然语言处理能力,为人类和机器之间的交互提供了新的可能性。也就是说,gpt的出现,大大降低了AI相关工具的开发难度的同时,也给很多工具开发的机会,API的调用是开发和调试工具的基础。
GPT API申请
目前能够获取API的方法并不多,这里会给出几种目前较为流行的获取方式。
OpenAI官方
OpenAI官方提供API支持,而且目前主流的工具都支持官方API的调用方式。缺点是API需要翻墙,并且支付很难,不支持国内任何信用卡支付,目前(2023年12月28日)很多国内的用户,为了支付API的费用,去开通美国或者新加坡等国外的信用卡,甚至开通很多灰产会使用的虚拟信用卡和虚拟货币(比如USDT,国外很多诈骗和赌博分子洗钱用虚拟货币)。
建议薅完开账号的送的几刀羊毛之后就可以不用了,这里也不提供虚拟信用卡的开卡经验,如果必须要使用官方API,用其他的咳嗽,最好去开新加坡的ICBC信用卡,至少属于正规渠道,网上有很多教程,这里不再赘述。
微软OpenAI
实际上就是business版本的OpenAI官方API,优点是相对支付方便,国内信用卡支付即可,而且提供的API不需要翻墙就可以使用。难点是需要公司邮箱来申请,如果有公司邮箱,现在直接申请,一般24小时内都会通过,而且通过之后,可以获取200刀的首月免费额度,同时API是可以在国内直接使用不需要翻墙。并且目前gpt-4也同时得到支持了,只需要更换地区就可以直接使用,月底统一结账。申请方法网上有很多现成的,这里也不再赘述。
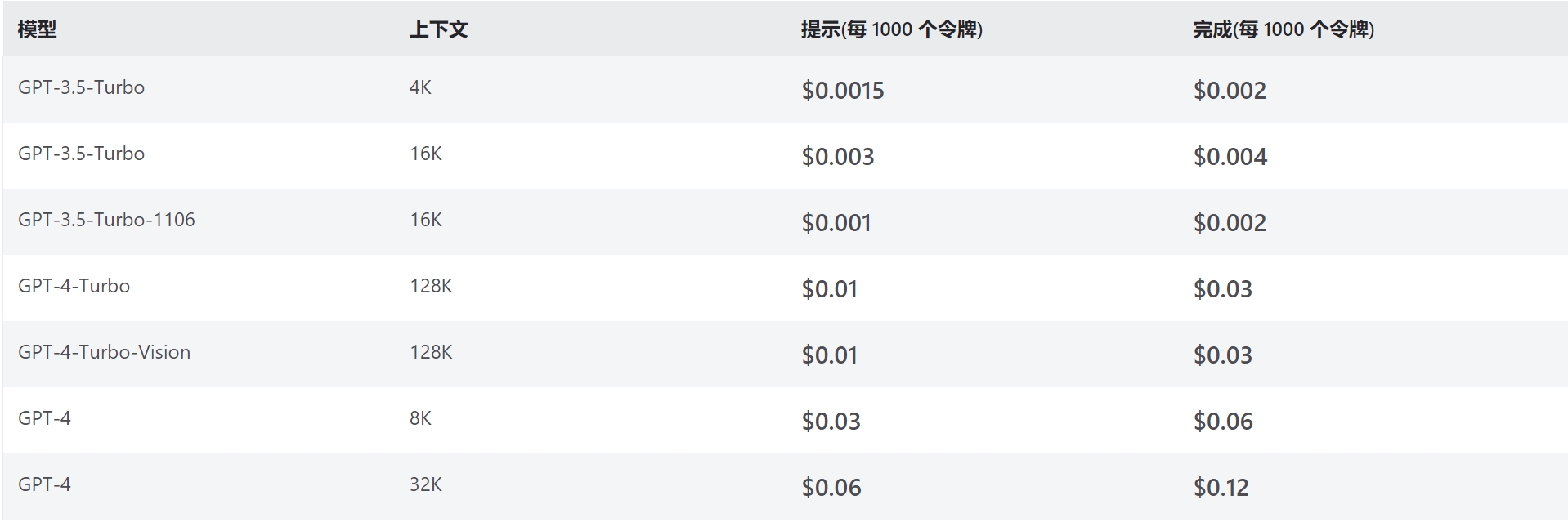
价格上基本上和OpenAI官方一致,切记一点,不要使用微软的微调模型,这是价格上最大的一点不同,如下图所示:
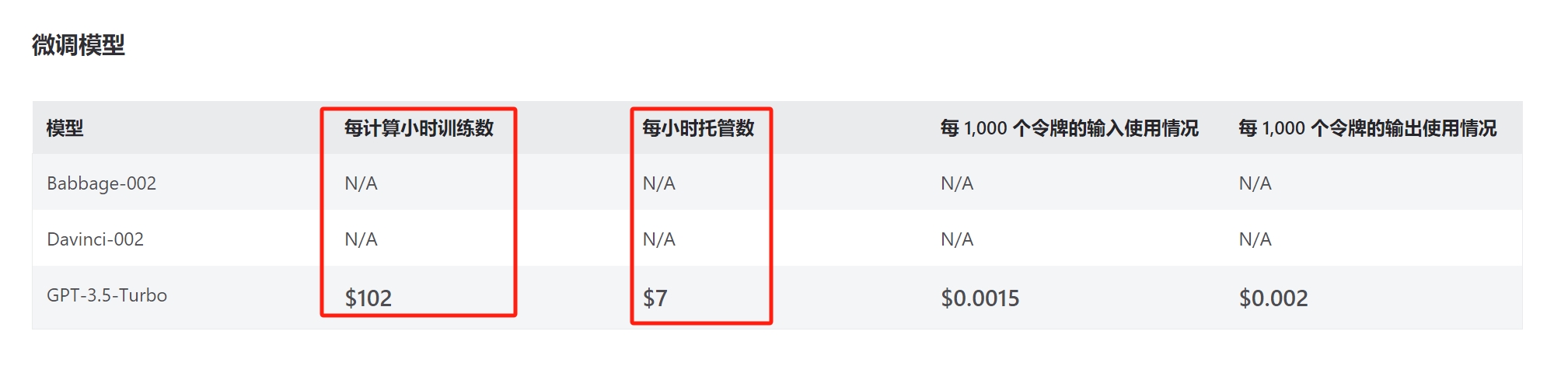
注意圈红的位置,这里就是微软和官方最大的不同,微调一次模型需要根据时间收费上百刀,并且微调模型运行时也会根据时间收费,而OpenAI官方微调是完全免费的。
这里建议如果必须要使用的微调模型的同学,务必使用官方提供的微调模型。目前使用微调模型主要是微调GPT-3.5模型,用以达到GPT-4.0的能力,由于目前已经推出了更便宜的GPT-4.0 turbo模型,完全可以使用提前喂上下文的GPT-4.0 turbo模型替代微调GPT-3.5模型。
第三方 or 其他
由于所有第三方最终都会指向收费的OpenAI官方或者微软OpenAI,所以长期价格上不可能低于OpenAI的价格,除非一些灰产,比如刷初始号送的,整体价格上会低于官方,但是使用上会非常麻烦,要经常更换API key。
我自己目前使用的方案是ChatGPT Plus + 微软OpenAI API,ChatGPT Plus使用美区Appstore+美区PayPal+国内信用卡绕开ChatGPT Plus的国内信用卡限制,微软OpenAI使用公司邮箱开通,支付上直接使用国内信用卡。
一方面ChatGPT Plus如果重度使用是非常划算得,这个如果之前有调用过API就知道API价格看起来便宜实际上是比较昂贵的。一方面开发工具和调试等,依赖API和OpenAI提供的调试平台,这个调试平台非常好用,下面会有介绍。
GPT API使用
这里使用上以微软的OpenAI介绍为主,其他都大同小异。
创建 Azure OpenAI
因为模型和地区限制有关,可能之前创建的时候选择的地区不对,可能导致有些模型是无法在该地区使用的,解决办法很简单,重新创建一个地区支持的就好。
比如美东不直接支持GPT-4.0模型,但是瑞典中部就直接支持。
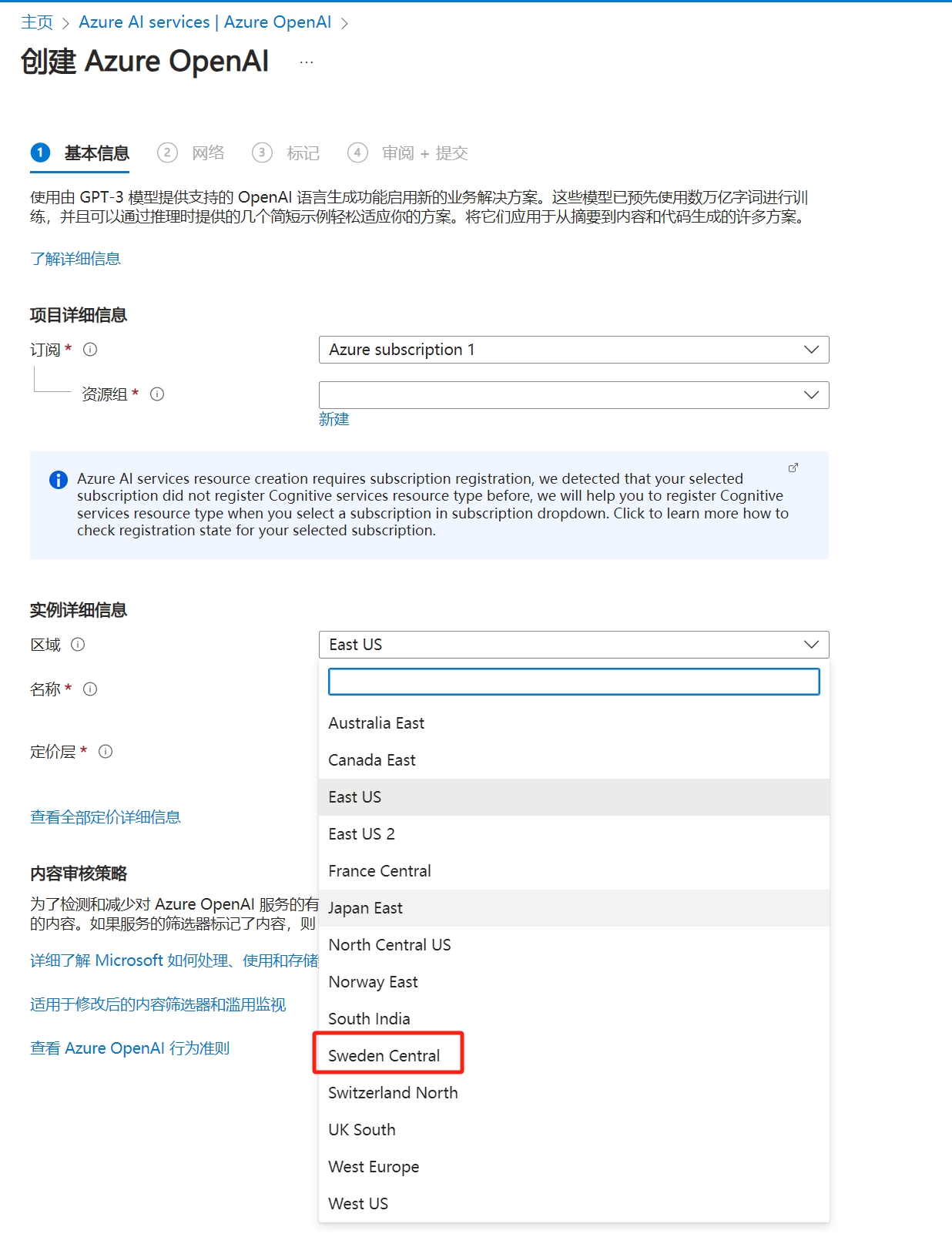
创建Azure OpenAI比较简单,如下图所示,先进入OpenAI服务,再点创建,填好其他信息之后,地区选瑞典中部并创建即可


部署模型
微软Azure是不断在更新模型的,目前(2023年12月29日)建议使用GPT-3.5-Turbo-1106和GPT-4-Turbo,相对价格,速度和准确度来说,都是非常不错的模型版本。
首先进入刚刚部署好的OpenAI服务,选择模型部署,目前模型部署已经换到另一个界面,所以点这里会跳转到新的模型界面。

进入该页面后,这里最重要的三个页面分别是聊天,部署和模型页面。
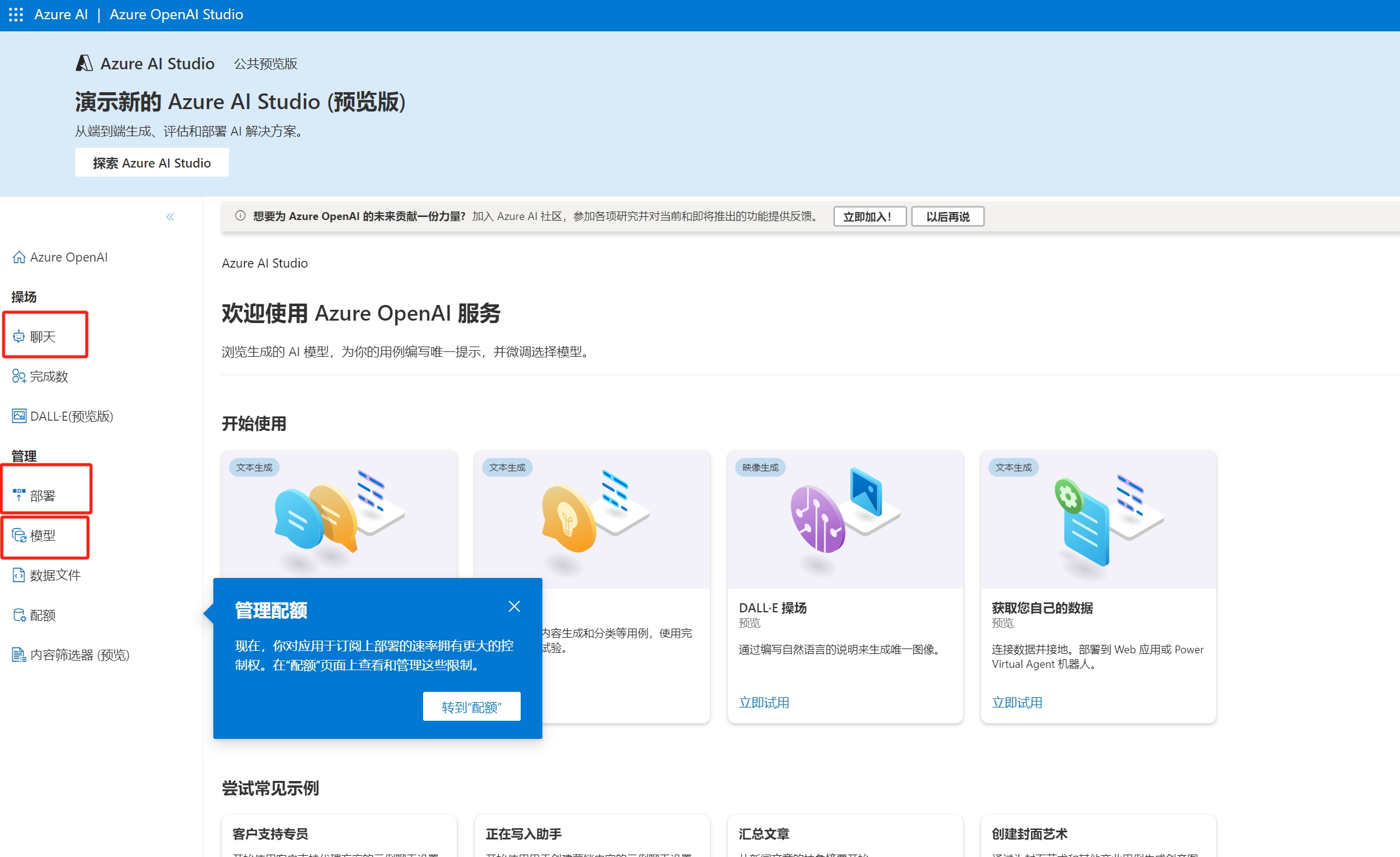
聊天页面提供了完整的GPT调试功能,后面选择好并部署好模型之后,可以通过该页面来进行调试,角色,一些基本的参数比如温度等,甚至该页面还提供了生成代码的功能,调试完成的功能直接转化成python代码提供给了用户。

部署页面提供了模型部署选项,实际上就是按需部署,可以选择模型的大版本和小版本,高级选项中也可以限制模型的使用速率,部署好的模型可以在聊天界面中选到并使用。
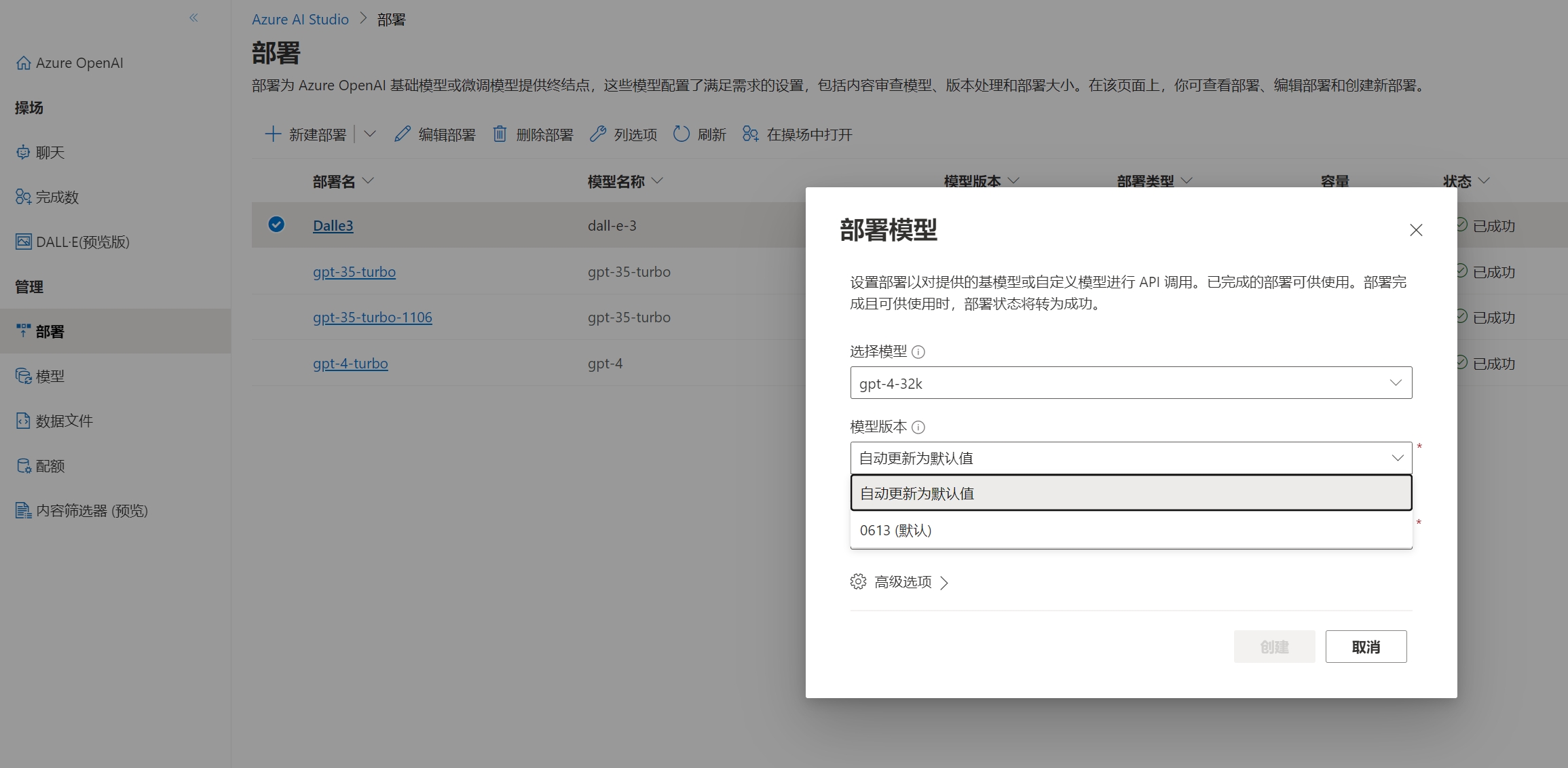
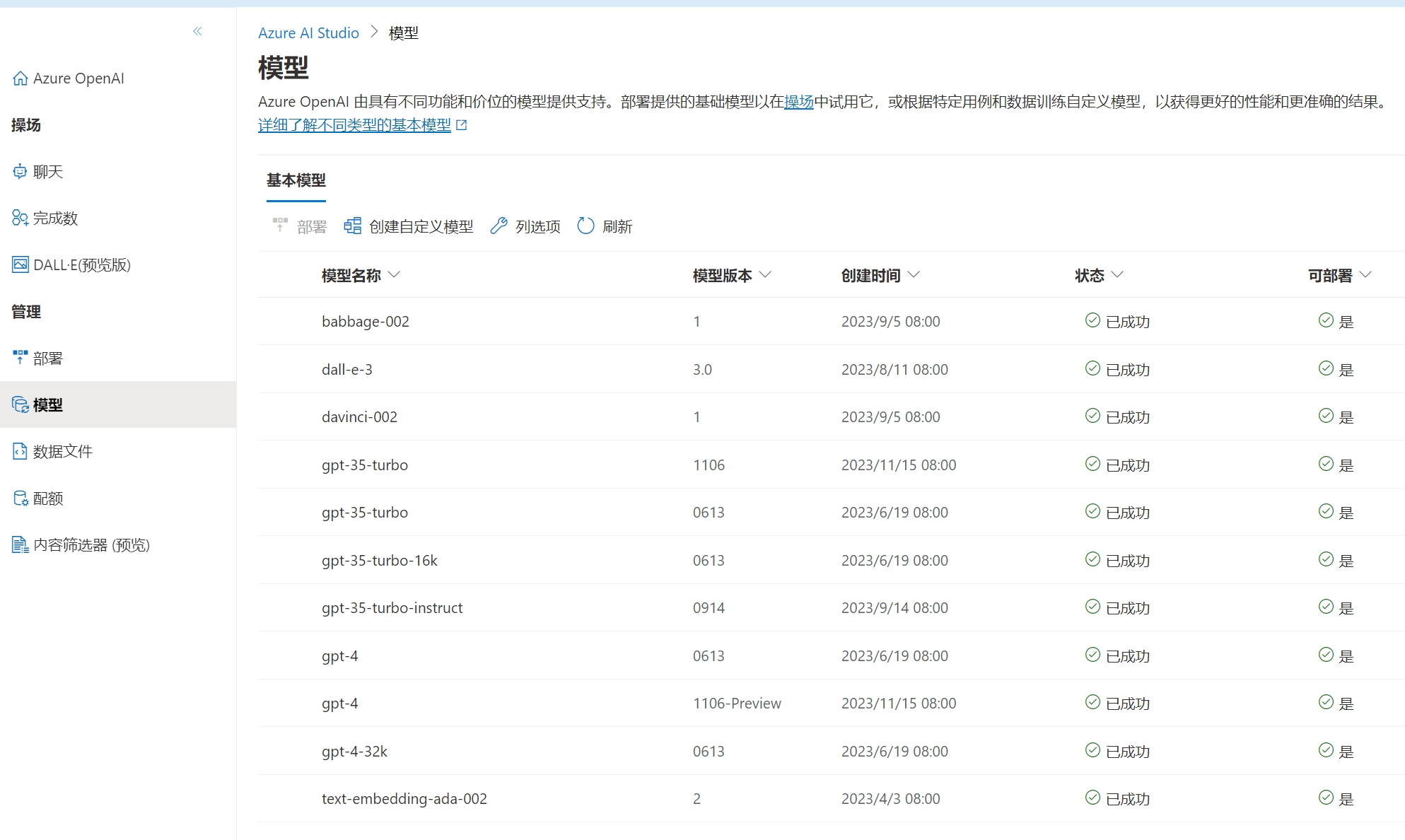
模型页面主要是界面当前地区和账户能部署哪些模型版本,这里会全部给出。并且这里提供了模型微调的功能,建议不要使用,这里就是之前提到的价格过于昂贵的微软Azure模型微调功能。
调试模型
选择好自己需要的模型,在部署页面配置完成后,就可以在聊天页面做调试。
调试这里重点说下功能:
首先是上图中模型,这里使用的是自己已经部署的模型,并不是官方提供的所有模型,模型一定要先部署才能使用。
除了模型选择功能外,也提供了显示当前使用tokens和会话数(上下文长度,超过了长度GPT会忘掉之前的对话)
切换到参数页面
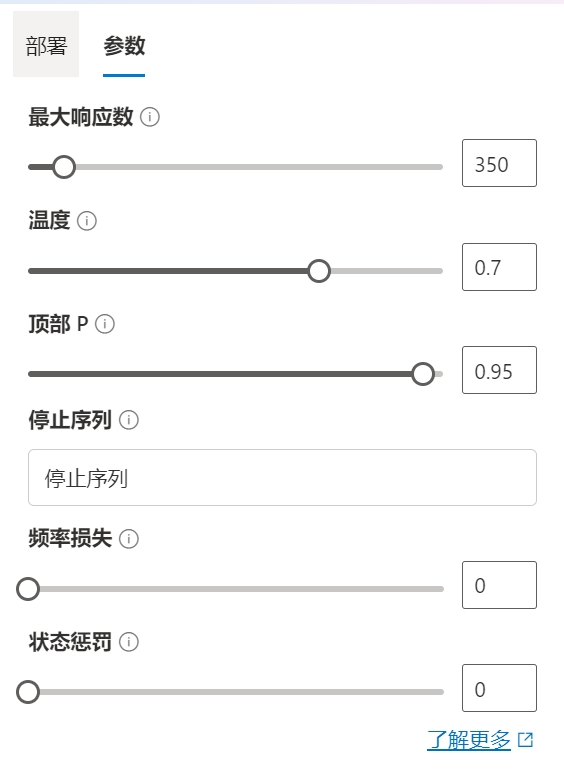
其他参数不再赘述,一般特殊需求才会使用到,自行查阅下后面的问号就懂了。
重点说下这个温度,在GPT模型(或类似的生成式模型)中,“温度”是一个用于调节生成文本的随机性的参数。高温度(接近1或更高):会增加文本生成的随机性,导致输出更加多样和不可预测。这可能会产生更创造性或不寻常的文本,但也可能降低文本的连贯性和准确性。低温度(接近0):会减少随机性,使模型更倾向于生成高概率(更常见、更安全)的文本。这通常会导致更一致、更准确的输出,但可能缺乏创造性。在不同的应用场景中,根据所需的输出类型选择合适的温度非常重要。例如,创意写作可能需要较高的温度来增加创新性,而事实性强、需要准确信息的场景(如新闻写作)可能更适合使用低温度。
模型调试时,还有另一个概念就是三种角色:user,assistant,system。我们如果之前使用过ChatGPT,user就代表我们的提问,assistant就是GPT的回复,assistant比较特殊,ChatGPT隐藏了assistant(助手)。“助手”是指GPT模型本身,它接收来自用户的输入并生成相应的输出。这个角色的主要任务是理解用户的请求,并基于训练和编程的指令来生成回答或执行任务。助手可以生成文本、回答问题、提供建议,甚至执行更复杂的任务,如编写代码或创作文本。在对话中,助手旨在提供有用、准确、及时的信息或帮助。可以简化理解是背景和角色相关设置等,ChatGPT已经给了默认的通用的assistant,减少了用户的使用成本。
其他功能比如显示对话的原始json,显示代码等,这里的功能主要是方便我们开发相关工具,比如显示代码这里,可以直接复制粘贴就可以在python等代码中使用。
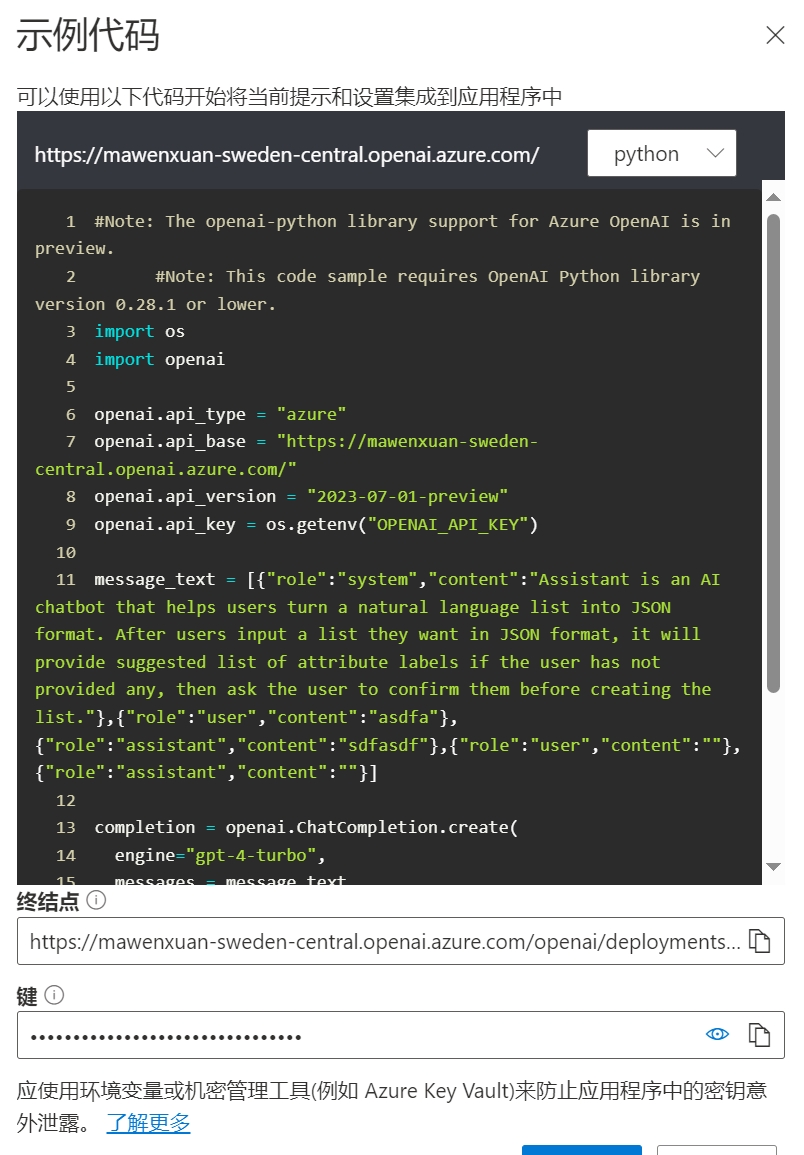
代码调用
gpt api的调用其实是很简单的,首先官方有给出非常详细的教程,而且甚至在调试时直接给出代码,只要修改下key配置好环境就可以直接调用。
如果英文比较好,建议阅读下官方的教程:https://platform.openai.com/docs/api-reference
这里因为之前有说过,微软Azure提供的API环境较好,所以API使用上以微软Azure为主,但是需要注意的是,虽然微软Azure提供的OpenAI的pip库和OpenAI官网使用的一致,但是调用上还是有区别的,区别点主要在于key的配置上。
这是OpenAI官方的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24
import openai # 填你的秘钥 openai.api_key = "这里填key" # 提问代码 def chat_gpt(prompt): # 你的问题 prompt = prompt # 调用 ChatGPT 接口 model_engine = "gpt-3.5-turbo-1106" completion = openai.Completion.create( engine=model_engine, prompt=prompt, max_tokens=1024, n=1, stop=None, temperature=0.5, ) response = completion.choices[0].text print(response)
展开
这是微软Azure的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
import os import openai openai.api_type = "azure" openai.api_base = "" openai.api_version = "2023-07-01-preview" openai.api_key = os.getenv("OPENAI_API_KEY") message_text = [{"role":"system","content":"You are an AI assistant that helps people find information."}] completion = openai.ChatCompletion.create( engine="gpt-4-turbo", messages = message_text, temperature=0.7, max_tokens=800, top_p=0.95, frequency_penalty=0, presence_penalty=0, stop=None )
展开
连接上微软Azure会比OpenAI官方要求更多的参数,这会导致很多情况下不能在一些OpenAI的套皮应用上支持微软Azure。
当然对于我们自己写代码的工具来说基本上毫无影响,而且由于接口来自于微软,国内不翻墙也可以正常使用该接口。
这里给出一个完整的多轮对话的使用微软Azure的脚本给大家抄作业
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
import os import openai # 设置 API 参数 openai.api_type = "azure" openai.api_base = "" # 在此处填写 Azure 的 API 基地址 openai.api_version = "2023-07-01-preview" openai.api_key = os.getenv("OPENAI_API_KEY") # 初始化对话历史 conversation_history = [ {"role": "system", "content": "You are an AI assistant that helps people find information."} ] def get_ai_response(message): # 将用户消息添加到对话历史 conversation_history.append({"role": "user", "content": message}) # 调用 AI 完成 API completion = openai.ChatCompletion.create( engine="gpt-4-turbo", messages=conversation_history, temperature=0.7, max_tokens=800, top_p=0.95, frequency_penalty=0, presence_penalty=0, stop=None ) # 将 AI 回复添加到对话历史 ai_response = completion.choices[0].message['content'] conversation_history.append({"role": "assistant", "content": ai_response}) return ai_response # 示例对话 print("AI:", get_ai_response("Hello, can you help me?")) user_input = input("User: ") print("AI:", get_ai_response(user_input))
展开
实际上可以对比上述代码,即可以发现与单论对话的区别就是多轮对话多了一个conversation_history,这个多出的conversation_history每次会将之前对话原封不动的传输给gpt,所以gpt才知道我们的上下文,这个conversation_history会导致成本增加很多,所以记得限制数量,比如10轮对话后遗忘之前更早的对话等方式。
API版本问题
从 2023 年 11 月 6 日开始,pip install openai 和 pip install openai –upgrade 将安装 OpenAI Python 库 version 1.x。更新之后接口的调用出现了些许不同。这里可以参考下微软Azure给出的不同点,尤其注意key相关和对话相关。
这里建议都升级到最新版本API,pip升级直接输入如下语句即可:
1
pip install openai --upgrade
展开
API调用和之前的不同,这里分别给出Azure的新老版本关于API调用的demo
1.x版本之前
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
import os import openai openai.api_type = "azure" openai.api_version = "2023-05-15" openai.api_base = os.getenv("AZURE_OPENAI_ENDPOINT") # Your Azure OpenAI resource's endpoint value. openai.api_key = os.getenv("AZURE_OPENAI_KEY") response = openai.ChatCompletion.create( engine="gpt-35-turbo", # The deployment name you chose when you deployed the GPT-3.5-Turbo or GPT-4 model. messages=[ {"role": "system", "content": "Assistant is a large language model trained by OpenAI."}, {"role": "user", "content": "Who were the founders of Microsoft?"} ] ) print(response) # To print only the response content text: # print(response['choices'][0]['message']['content'])
展开
1.x版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
import os from openai import AzureOpenAI client = AzureOpenAI( api_key = os.getenv("AZURE_OPENAI_KEY"), api_version = "2023-05-15", azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT") ) response = client.chat.completions.create( model="gpt-35-turbo", # model = "deployment_name". messages=[ {"role": "system", "content": "Assistant is a large language model trained by OpenAI."}, {"role": "user", "content": "Who were the founders of Microsoft?"} ] ) #print(response) print(response.model_dump_json(indent=2)) print(response.choices[0].message.content)
展开
多轮对话的demo这里也给出
1.x前版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
import os import openai openai.api_type = "azure" openai.api_version = "2023-05-15" openai.api_base = os.getenv("AZURE_OPENAI_ENDPOINT") # Your Azure OpenAI resource's endpoint value. openai.api_key = os.getenv("AZURE_OPENAI_KEY") conversation=[{"role": "system", "content": "You are a helpful assistant."}] while True: user_input = input() conversation.append({"role": "user", "content": user_input}) response = openai.ChatCompletion.create( engine="gpt-35-turbo", # The deployment name you chose when you deployed the GPT-35-turbo or GPT-4 model. messages=conversation ) conversation.append({"role": "assistant", "content": response["choices"][0]["message"]["content"]}) print("\n" + response['choices'][0]['message']['content'] + "\n")
展开
1.x版本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
import os from openai import AzureOpenAI client = AzureOpenAI( api_key = os.getenv("AZURE_OPENAI_KEY"), api_version = "2023-05-15", azure_endpoint = os.getenv("AZURE_OPENAI_ENDPOINT") # Your Azure OpenAI resource's endpoint value. ) conversation=[{"role": "system", "content": "You are a helpful assistant."}] while True: user_input = input("Q:") conversation.append({"role": "user", "content": user_input}) response = client.chat.completions.create( model="gpt-35-turbo", # model = "deployment_name". messages=conversation ) conversation.append({"role": "assistant", "content": response.choices[0].message.content}) print("\n" + response.choices[0].message.content + "\n")
展开
上述demo更改下连接方式即可在对应版本下成功运行。
有个关于文档的小技巧这里提示下:
一般使用上的文档建议使用微软的Azure OpenAI相关,分类规范,支持多国语言,而且其实他同时给出了OpenAI的API使用说明和Azure OpenAI的API使用说明,甚至对比给出如何切换。。。
新功能发布务必关注下OpenAI的官网给出的通知
一般OpenAI和Azure的能力会同步更新,也就是说模型的更新和新功能等都会同步发布,Azure可能相对会晚一些,因为Azure OpenAI的设计就是面向Business,和操作系统和软件类似,商用版本更追求稳定性,所以在新功能上不会非常激进。